对getBytes()的一点疑问
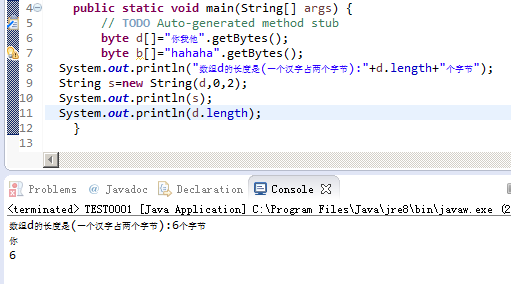
我输入的程序是这样的
byte d[]="你我他".getBytes();
byte b[]="hahaha".getBytes();
System.out.println("数组d的长度是(一个汉字占两个字节):"+d.length+"个字节");
String s=new String(d,0,2);
System.out.println(s);
System.out.println(d.length);
这是得到的结果
数组d的长度是(一个汉字占两个字节):9个字节
�
9
不太理解为什么一个汉字占两个字节,"你我他"的长度却是9
还有运行结果的第二行那个问号是啥意思啊?
汉字使用gbk,utf-8的编码所占的字节长度不一样;第二行是乱码截取有问题。你可以参考下面
byte[] t_iso = "你我他".getBytes("ISO8859-1");
byte[] t_gbk = "你我他".getBytes("GBK");
byte[] t_utf8 = "你我他".getBytes("utf-8");
byte b[] = "hahaha".getBytes();
System.out.println("数组d的长度是(一个汉字占两个字节):" + t_utf8.length + "个字节");
String s = new String(t_utf8);
System.out.println(s);
System.out.println(t_iso.length);
System.out.println(t_gbk.length);
System.out.println(t_utf8.length);
byte不识别中文的,你把字符型转换为字节型它会出现乱码,你可以把d打印出来试试
编码方式不一样,GBK和UTF-8占的字节可能不一样
首先,java对汉字的处理采用的是utf-8的编码格式,所以一个汉字是占据三个字节的;
其次,你这里new String(d,0,2)得到的是中文乱码,说明你的工作空间的编码不是utf-8。我这里测试的结果是"你"。