xlrd正确使用方式?还能简单吗?
#coding: utf8
import re
import xlrd
def get_excel():
###文件绝对路径
xfile=r'D:\test.xlsx'
book=xlrd.open_workbook(xfile)
###打开第3个SHEET页
table=book.sheets()[0]
###标识字典
b_list={}
biaoshi=''
###获取行数和列数
nrows=table.nrows
ncols=table.ncols
target_list=[]
target_list2=[]
###获取标识头
for i1 in range(ncols):
for j in table.col_values(i1):
b_list[i1]=j
break
###打印表头
for i2 in b_list:
print i2,b_list[i2]
biaoshi=biaoshi+b_list[i2]+' '
###在列里面进行查询
tiaojian=int(raw_input(u'请输入你要查询条件的次数:\n'))
for i in range(tiaojian):
chaxun1=int(raw_input(u'请输入你要查询的字段对应号(参照上图):\n'))
chaxun_neirong=raw_input(u'请输入你要查询的字段内容:\n')
#####判断搜索数据在哪行并打印
for k in range(nrows):
huajian=table.cell(k,chaxun1).value
try:
huajian=str(huajian)
except:
pass
try:
if re.search(chaxun_neirong,huajian).group():
if k in target_list:
target_list2.append(k)
else:
target_list.append(k)
except:
pass
if len(target_list)>len(target_list2) and target_list2 != []:
target_list=target_list2
target_list2=[]
else:
pass
print biaoshi
for fi in target_list:
for fi1 in table.row_values(fi):
print fi1,
print '\n'
get_excel()
#coding: utf8
import re
import xlrd
def get_excel():
###文件绝对路径
xfile=r'D:\test.xlsx'
book=xlrd.open_workbook(xfile)
###打开第3个SHEET页
table=book.sheets()[0]
###标识字典
b_list={}
biaoshi=''
###获取行数和列数
nrows=table.nrows
ncols=table.ncols
target_list=[]
target_list2=[]
###获取标识头
for i1 in range(ncols):
for j in table.col_values(i1):
b_list[i1]=j
break
###打印表头
for i2 in b_list:
print i2,b_list[i2]
biaoshi=biaoshi+b_list[i2]+' '
###在列里面进行查询
tiaojian=int(raw_input(u'请输入你要查询条件的次数:\n'))
for i in range(tiaojian):
chaxun1=int(raw_input(u'请输入你要查询的字段对应号(参照上图):\n'))
chaxun_neirong=raw_input(u'请输入你要查询的字段内容:\n')
input_list=[]
linshi=''
print input_list
for i in chaxun_neirong:
if i == ',':
input_list.append(linshi)
linshi=''
else:
linshi=linshi+i
input_list.append(linshi)
print input_list
#####判断搜索数据在哪行并打印
for k in range(nrows):
huajian=table.cell(k,chaxun1).value
try:
huajian=str(huajian)
except:
pass
for shuru in input_list:
try:
if re.search(shuru,huajian).group():
if k in target_list:
target_list2.append(k)
break
else:
target_list.append(k)
break
except:
pass
print target_list,target_list2
if len(target_list)>len(target_list2) and target_list2 != []:
target_list=target_list2
target_list2=[]
else:
pass
print biaoshi
for fi in target_list:
for fi1 in table.row_values(fi):
print fi1,
print '\n'
get_excel()
ana=''
sql_list=[]
sql_begin=''
sql_end='values('
sql_linshi=''
sql_values_list=[]
c=0
c1=0
c2=0
iput=[]
iput_linshi=[]
iputall=[]
iput_ana=''
iput_sql=raw_input('输入sql语句:\n')
for i in iput_sql:
c=c+1
if i=='(':
ana=''
elif i==',':
sql_list.append(ana)
ana=''
elif i==')':
sql_list.append(ana)
sql_begin=iput_sql[:c]
break
else:
ana=ana+i
for j in range(len(sql_list)):
iputall.append(iput)
for k in sql_list:
iput_linshi=[]
print '输入%s的值' % k
value=raw_input('')
for va in value:
if va == ',':
iput_linshi.append(iput_ana)
iput_ana=''
else:
iput_ana=iput_ana+va
print 'iput_linshi' ,iput_linshi
for m in range(len(iputall)):
print 'm',m
for n in range(len(sql_list)):
print 'n',n
if n==c1 and m==c1:
iputall[m]=iput_linshi
print iputall[m]
break
else:
pass
c1=c1+1
print iputall
传统MVC模型
模型(model)-视图(view)-控制器(controller)
MTV也是MVC的一种,但是C层被django自行处理,所以Django更关注的是模型(Model)、模板(Template)和视图(Views)
django(MTV框架)
M 代表模型(Model),即数据存取层。 处理与数据相关的所有事务: 如何存取、如何验证有效性、包含哪些行为以及数据之间的关系等。
T 代表模板(Template),即表现层。 处理与表现相关的决定: 如何在页面或其他类型文档中进行显示。
V 代表视图(View),即业务逻辑层。包含存取模型及调取恰当模板的相关逻辑。 模型与模板之间的桥梁。
以我的博客为例
根目录下包含的文件: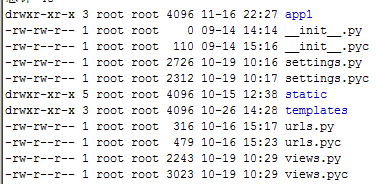
app1中包含了model.py(M),相应代码: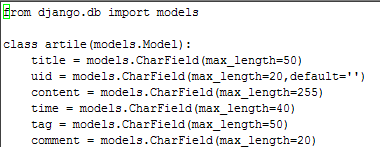
运用这个类,来创建、检索、更新、删除 数据库中的记录而无需写一条又一条的SQL语句
views.py(V)中相应代码:
简单的说Article这个函数要返回一个页面
对应的urls.py中相应代码: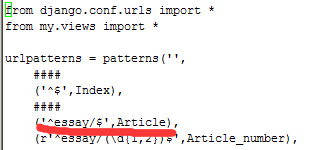
通过访问www.hamals.com/essay就可以访问上面article.html这个页面
对于article.html之类的静态文件和CSS,JS,img等文件放入templates文件夹即可
django的优点:
1.自助管理后台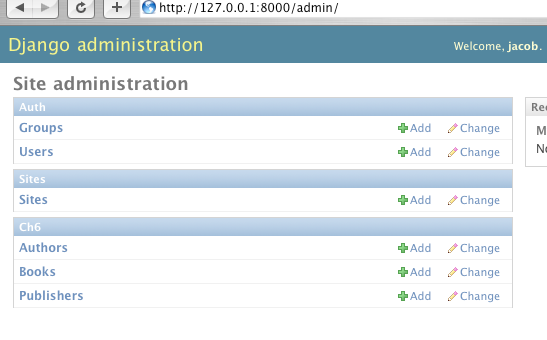
settings.py文件简单设置即可
2.提供一系列的比较成熟的解决方案
3.快速上手
缺点:
性能?
