同一编码方式的URLEncode.encode()方法与getBytes()方法返回的十六进制不同?
问题如标题啦
写了一个测试demo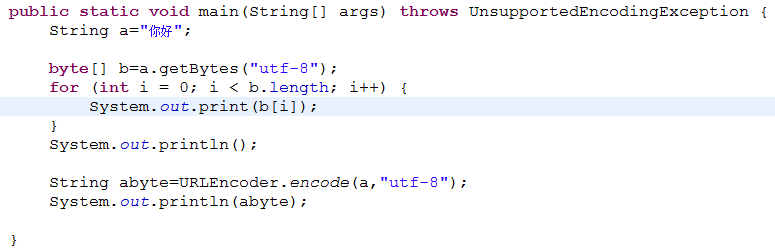
运行结果:
-28-67-96-27-91-67
%E4%BD%A0%E5%A5%BD
很奇怪为什么都是用UTF-8编码返回字节,但返回的十六进制为什么不同呢?
a.getBytes('utf-8') 若a字符串为中文的时候,因为utf-8的中文是3字节,所以一个中文字会输出3个ascii码。“你好”两个中文字,输出6个ascii码
a.getBytes('GB2312') 若a字符串为中文的时候,因为gb2312的中文是2字节,所以一个中文字会输出2个ascii码。“你好”两个中文字,输出4个ascii码
Bytes 是字节的意思啊,你无论放什么参数还是ascii码的编号
utf8本来是用于国际通用的字符编码,一个中文字有3个字节也就是24个位的数据。因为老外的电脑有些不支持utf-8字符,然后只能显示ascii码。
所以网址为了通用性很有必要转换成16进制 16进制全是英文和几个符号