const的这段话怎么理解,从底层解释解释,谢谢
 const
const
通常一个程序可以分为代码段,数据段(数据段又可分为只读数据段,可读写数据段),BSS未初始化数据段,堆,栈,前三个是在编译器决定的,会最终影响目标文件的大小,后三个是在运行时才会产生的...明显的const常量是只读的,所以他被分配到只读代码段,因为他的属性决定了他是不可更改的,所以编译器可以对同样引用相同常量的变量进行优化,是他们同时指向相同的常量字段,而又不互相影响,const的字段是会出现在汇编文件与目标文件中的,而#define的宏定义的变量,编译器在进行编译的时候会根据定义对目标字段进行替换,并不会转变为汇编代码,#define是预处理符,在预处理阶段所有的PI都已经被替换为了3.14159,所有的头文件被包含进来...得到新的*.i程序文本,所以说参与编译的时候等于说是分别定义了double J=3.1415,double j=3.1415对应于多个内存拷贝...而const同上面所述,可以认为是对Pi的常量引用,编译器处理的
#define PI 3.14159
const double Pi=3.14159
int main(){
double I=PI;
double i=Pi;
return 0;
}
得到的汇编代码如下,清楚明了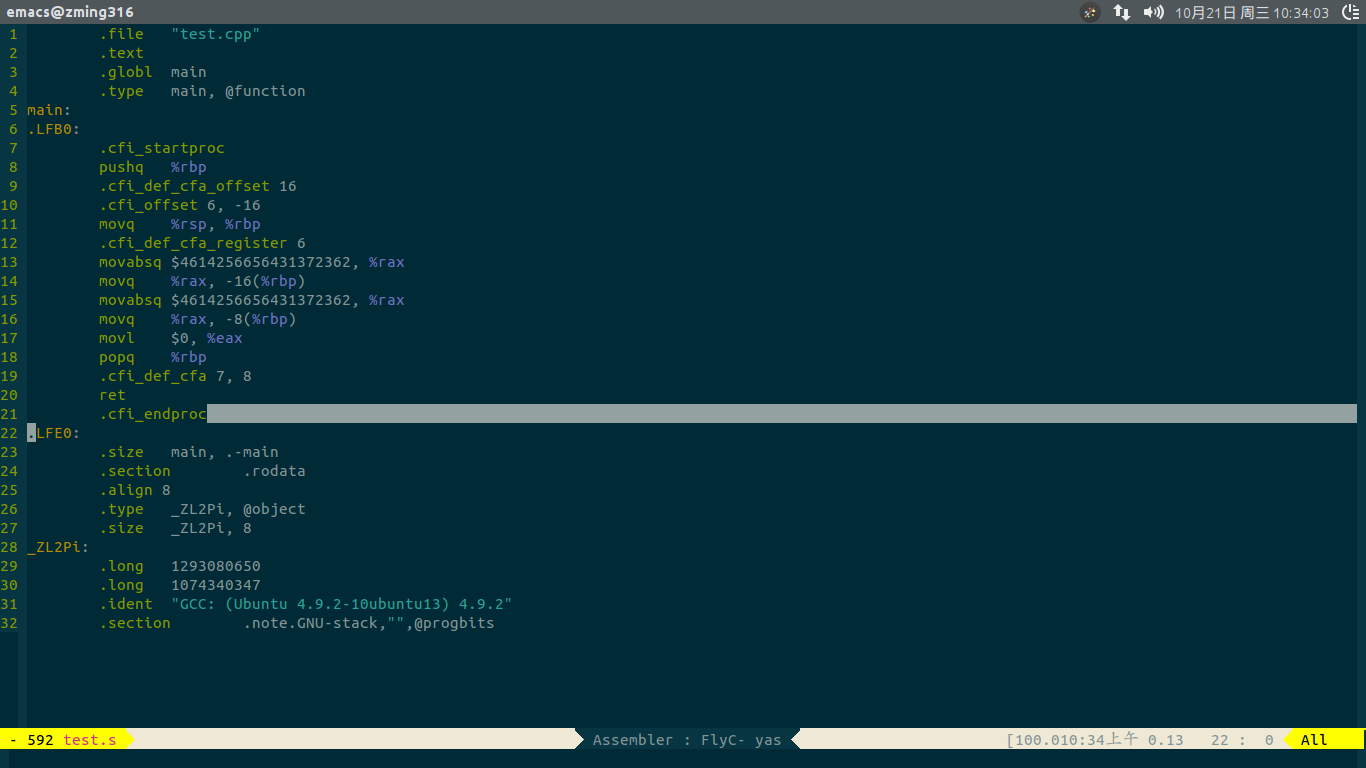 ,可以发现Pi对应汇编中的相应的常量字段..
,可以发现Pi对应汇编中的相应的常量字段..
但是对于内置简单类型来说,有些编译器并不会采用只开辟一个内存的方法,通过简单的汇编代码查看,我们也能发现实际上const的数据还是占用了多份内存
#define PI 3.14
const double Pi=5.1415926;
int main(){
double s1=PI;
double s2=Pi;
double s3=Pi;
double s4=Pi;
return 0;
}
.file "test.cpp"
.text
.globl main
.type main, @function
main:
.LFB0:
.cfi_startproc
pushq %rbp
.cfi_def_cfa_offset 16
.cfi_offset 6, -16
movq %rsp, %rbp
.cfi_def_cfa_register 6
movabsq $4614253070214989087, %rax
movq %rax, -32(%rbp)
movabsq $4617474937056750629, %rax
movq %rax, -24(%rbp)
movabsq $4617474937056750629, %rax
movq %rax, -16(%rbp)
movabsq $4617474937056750629, %rax
movq %rax, -8(%rbp)
movl $0, %eax
popq %rbp
.cfi_def_cfa 7, 8
ret
.cfi_endproc
.LFE0:
.size main, .-main
.section .rodata
.align 8
.type _ZL2Pi, @object
.size _ZL2Pi, 8
_ZL2Pi:
.long 2794023973
.long 1075089661
.ident "GCC: (Ubuntu 4.9.2-10ubuntu13) 4.9.2"
.section .note.GNU-stack,"",@progbits
但对于复杂内型,编译器应该就会采用理论上的策略吧...
const定义的变量是有内存分配的,在第一使用的时候对变量分配内存,而且在对const变量的后续使用中,全部都是指向一块内存,而且编译器对const变量支持类型检查;
而define定义的常量宏并没有内存分配,在每次每个程序编译之前有个预编译,预编译进行了简单的宏替换当然也就没有类型检查;
const的实现方式在C和C++中还略有不同,在C++中简单的const变量并没有内存空间,也是执行一个替换的过程。