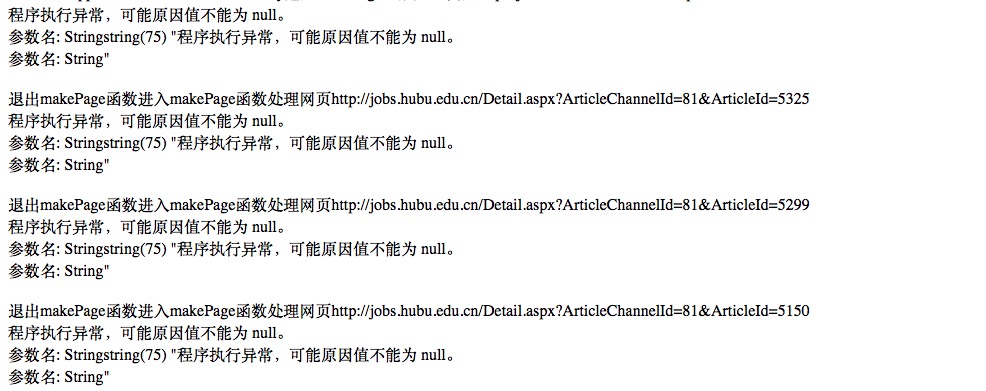
使用curl单独抓取http://jobs.hubu.edu.cn/Detail.aspx?ArticleChannelId=81&ArticleId=5722可行,但是如果抓取相同类型的一系列网站就会出错,将他们放在数组$linkList中,分别是http://jobs.hubu.edu.cn/Detail.aspx?ArticleChannelId=81&ArticleId=5722,http://jobs.hubu.edu.cn/Detail.aspx?ArticleChannelId=81&ArticleId=5325等等。
http://www.jb51.net/article/48956.htm