正则表达式区分HTML中类似的两行
最近在学习正则表达式,从网上down数据的时候遇到点问题,就像下面这两个图片上红色圈起来的位置一样,怎么用正则式区别HTML源码中的两个类似的字段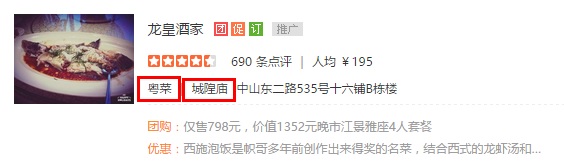
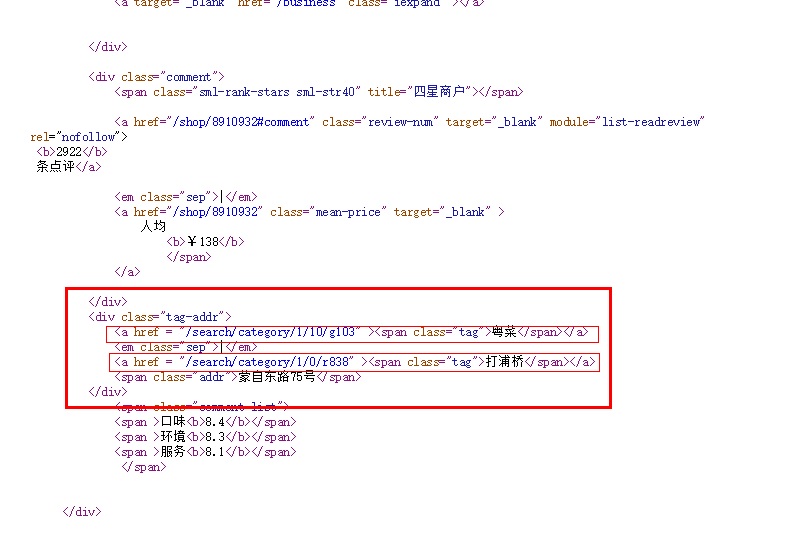
什么意思?,可以先识别出tag-addr,然后接下来就好识别了
下面的正则获取tag里面的内容,自己在对内容分析下获取你的数据
<div class="tag-addr">([\s\S]+?)</div>
这里说的 shell + 正则表达式的方式:
(1) 利用grep提权tag-addr的信息:
** grep -A 5 -E “tag-addr”**

(2)在上面的基础上,使用正则表达式 tag,提取对应行
** grep -A 5 -E “tag-addr” | grep -E “tag”**
(3)在提取的结果中,你在截取你想要的值:“粤菜”,“城隍庙”
$1第一个,$2第二个;
<div class=\"tag\-addr\">(<a href=.*</a>)\s*<em class=\"sep\">\|</em>\s*(<a href=.*</a>)<span class=\"addr\">.*</span></div>