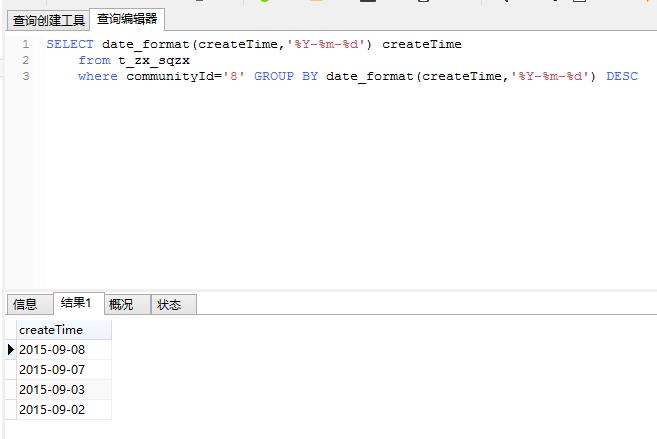
sql语句问题,怎么将查询出来的数据,只取第2第3条数据
SELECT date_format(createTime,'%Y-%m-%d') createTime
from t_zx_sqzx
where communityId='8' GROUP BY date_format(createTime,'%Y-%m-%d')
DESC
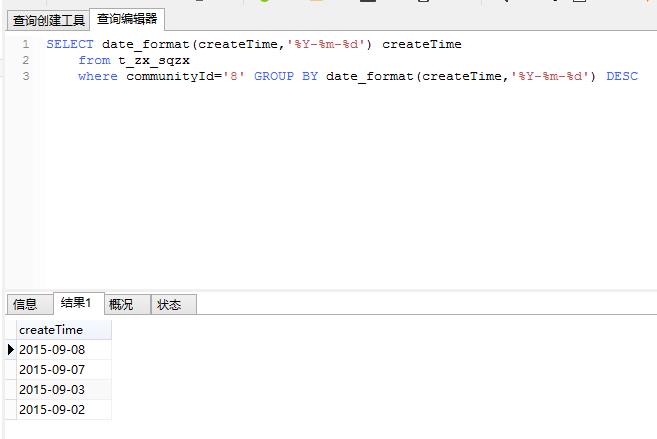
这是从数据库读取出的数据,怎么取第2第3条数据,或者其他条数据
看不出来你用的是啥数据库。mysql 是 limit 2,3 前面三条,然后oracle是rownum
在语句最后加 limit startIndex,num 如 limit 2,2
其中startIndex表示第二条数据开始取,
num表示取几条数据
参考地址:http://www.cnblogs.com/yunf/archive/2011/04/12/2013448.html
7.记录搜索:
开头到N条记录
Select Top N * From 表
N到M条记录(要有主索引ID)
Select Top M-N * From 表 Where ID in (Select Top M ID From 表) Order by ID Desc
N到结尾记录
Select Top N * From 表 Order by ID Desc
案例
例如1:一张表有一万多条记录,表的第一个字段 RecID 是自增长字段, 写一个SQL语句,找出表的第31到第40个记录。
select top 10 recid from A where recid not in(select top 30 recid from A)
分析:如果这样写会产生某些问题,如果recid在表中存在逻辑索引。
select top 10 recid from A where……是从索引中查找,而后面的select top 30 recid from A则在数据表中查找,这样由于索引中的顺序有可能和数据表中的不一致,这样就导致查询到的不是本来的欲得到的数据。
解决方案
1, 用order by select top 30 recid from A order by ricid 如果该字段不是自增长,就会出现问题
2, 在那个子查询中也加条件:select top 30 recid from A where recid>-1
例2:查询表中的最后以条记录,并不知道这个表共有多少数据,以及表结构。
set @s = 'select top 1 * from T where pid not in (select top ' + str(@count-1) + ' pid from T)'
print @s exec sp_executesql @s
如果是在MySQL中使用TOP会有问题。
解决方法:http://blog.163.com/budong_weimin_zh/blog/static/12919852420115130484204/
between and
设一个行标,rownum,ruwid之类的
limit(index,count):
index从哪里开始取,count取几条
SELECT date_format(createTime,'%Y-%m-%d') createTime
from t_zx_sqzx
where communityId='8' GROUP BY date_format(createTime,'%Y-%m-%d')
DESC limit 1,1(取第二条)
SELECT date_format(createTime,'%Y-%m-%d') createTime
from t_zx_sqzx
where communityId='8' GROUP BY date_format(createTime,'%Y-%m-%d')
DESC limit 2,1(取第三条)