php 模拟手机访问页面并抓取数据
$ch = curl_init();
$timeout = 0;
curl_setopt($ch, CURLOPT_CONNECTTIMEOUT, $timeout);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
curl_setopt($ch, CURLOPT_HTTPHEADER, array(
'User-Agent: Mozilla/5.0 (iPhone; CPU iPhone OS 8_0 like Mac OS X) AppleWebKit/600.1.3 (KHTML, like Gecko) Version/8.0 Mobile/12A4345d Safari/600.1.4'));
$url = “http://search.shopping.yahoo.co.jp/search?p=%E9%9D%B4%E4%B8%8B&cid=&aq=-1&oq=&ei=UTF-8&first=1&tab_ex=commerce&sc_i=shp_pc_search_searchBox&mcr=2bfff23b09f55e9cac4a596fa6ab2f9f&ts=1439864569”;
curl_setopt($ch, CURLOPT_URL, $url);
$contents = curl_exec($ch);
print_r($contents);
理论上打印出来的$contents应该等于url对应的页面,如下图1-1: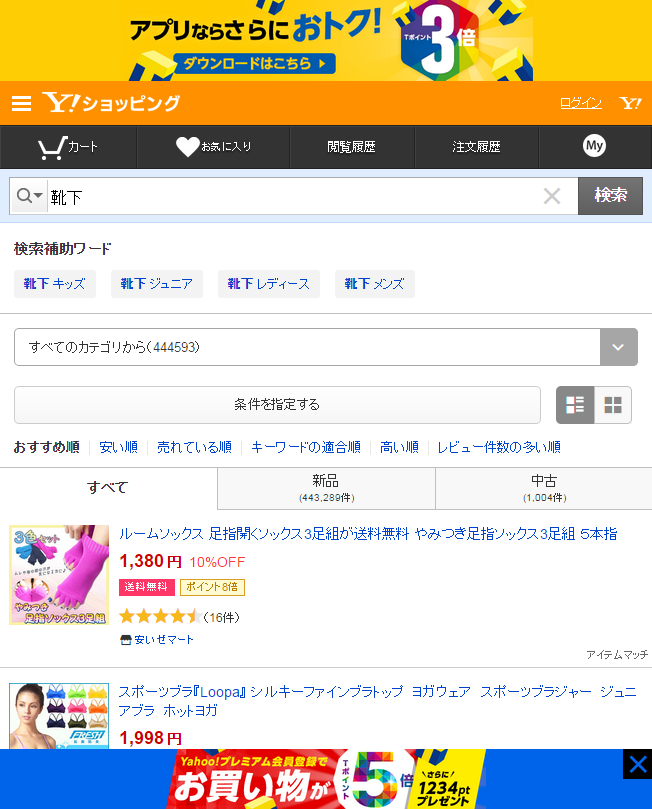
图1-1
但实际上,跳转到了另外一个url对应的页面,如下图1-2: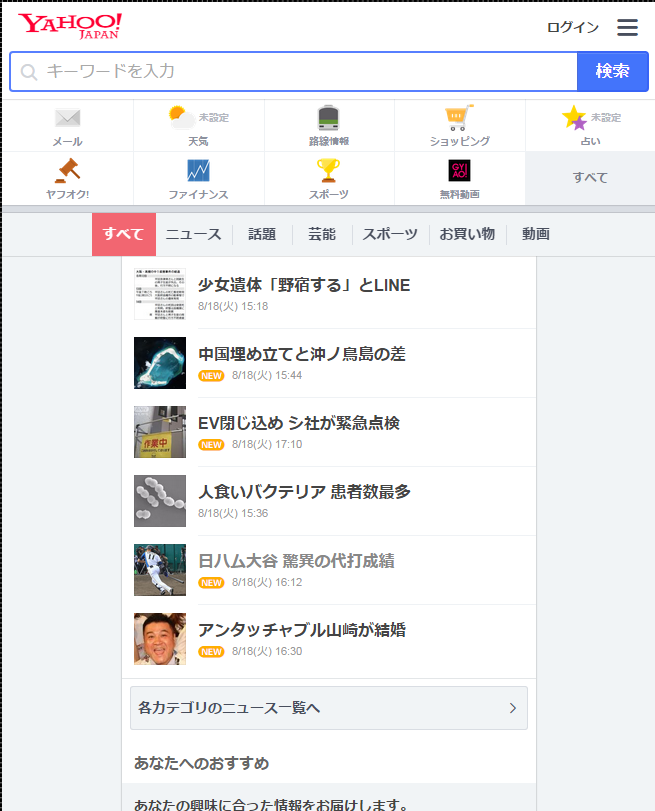
图1-2
只有在抓取日本yahoo的时候才出现的这种情况,抓取日本乐天页面都是正常。
1).这是什么原理导致的?
2).如何不让页面跳转,正确的取得页面?
用ip去取相应信息试试,也可能是网站做了反抓取措施。