jsoup怎么获取两个标签之间的text?
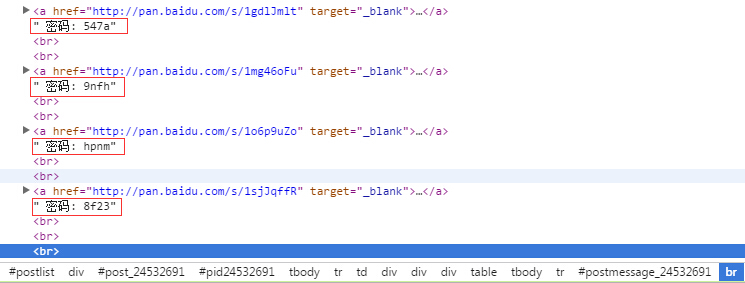
这是开发者工具解析到的一个论坛页面结构。。
可以看到每一个a标签和br标签之间总会夹着一个text,,也就是密码文本。而我根据网上的
API教程:
siblingA ~ siblingX: 查找A元素之前的同级X元素,比如:h1 ~ p
写成这样
Elements links_1 = tdsm.select("#postmessage_24532691>br~text");
然后打印_links_1.size为0.也就是并没有匹配到一个元素,,_
特此求正确写法
Element对象的textNodes()或ownText()方法。
以下是官方文档的内容:
For example, with the input HTML: <p>One <span>Two</span> Three <br> Four</p> with the p element selected:
p.text() = "One Two Three Four"
p.ownText() = "One Three Four"
p.children() = Elements[<span>, <br>]
p.childNodes() = List<Node>["One ", <span>, " Three ", <br>, " Four"]
p.textNodes() = List<TextNode>["One ", " Three ", " Four"]
没人吗?用了正则表达式好繁琐啊,,怎么写都没办法使超链接和密码一一对应,只能用jsoup截取超链接,正则表达式截取密码,,不能一一对应这也就意味着一个超链接可能要两三个密码才能匹配正确,有点拖时间啊。。
解决了吗?我刚好也遇到这个问题,有什么好办法吗?
解决了吗?我刚好也遇到这个问题,有什么好办法吗?
.textNodes() 用这个方法就能取到子节点中的所有文本节点