数据库一项特殊的统计,求高效率点的算法
有一个数据表
ID time pos result
1 15:00:1 1 true
1 15:00:1 2 true
1 15:00:1 3 true
1 15:00:1 4 true
1 15:00:2 1 true
1 15:00:2 2 true
3 15:00:1 1 true
3 15:00:1 2 False
3 15:00:1 3 true
3 15:00:1 4 true
如上: 在ID time 作为唯一标识的情况下 Pos项要有1 2 3 4 四项全有才算一组完整数据, 如果其result全为true则为true, 例: 1 15:00:1为true
同理 3 15:00:1 为 false, 1 15:00:2 为无效数据
如果有多项 ID 为 1的完整数据 ,则统计时以最晚的为准
整个数据库少的有几千行,多的有几万,我要统计其true的比例,而且怎么样统计才是效率较高呢?? SQL能做到?
select * from table a where exists(select pk from (select count(*) n ,pk from table group by pk) b where a.pk = p.pk and n >3) and result = true
这个应该比较完整
select * from table where pos in (1,2,3,4) and result =true
太那个了,哪有这样做Table的primary key
在 Oracle 10g 中试验 其它数据库可能得换函数
原始数据
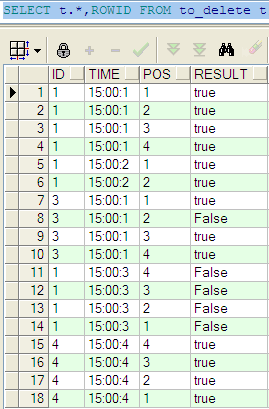
##分组 取目标result
SELECT t.id,t.time,SUM(POS) pos2,MIN(t.result) res,ROW_NUMBER() OVER (PARTITION BY t.id ORDER BY t.time DESC) AS rn
FROM to_delete t GROUP BY t.id,t.time ORDER BY id,t.time DESC
##统计
SELECT t3.res,COUNT(1) c FROM (
SELECT t.id,t.time,SUM(POS) pos2,MIN(t.result) res,ROW_NUMBER() OVER (PARTITION BY t.id ORDER BY t.time DESC) AS rn
FROM to_delete t GROUP BY t.id,t.time ORDER BY id,t.time DESC
) t3 WHERE t3.pos2=10 AND rn=1 GROUP BY t3.res