PHP mb_strlen()的诡异事件
额,之前的图片是错的,这张是对的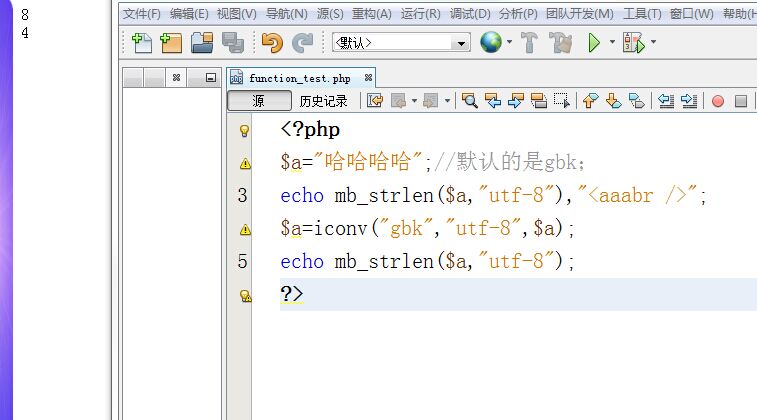
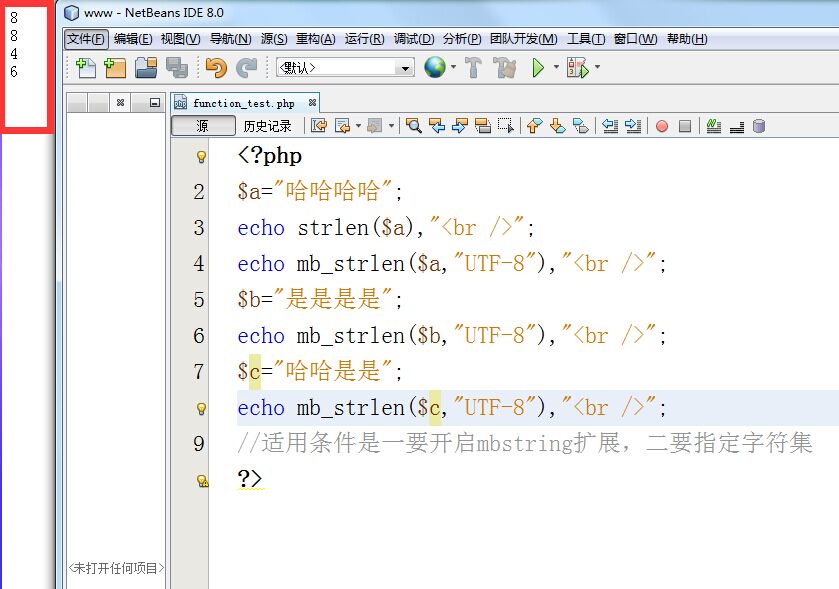
我遇到过相似的问题,答案可能是这样子的:“是”因为编码的原因,被认为是占一个字节,“哈”被认为占两个字节,所以才会有这个问题。而具体哪些汉字占一个字节,应该不多,属于个别现象。
不同的编码是不同的
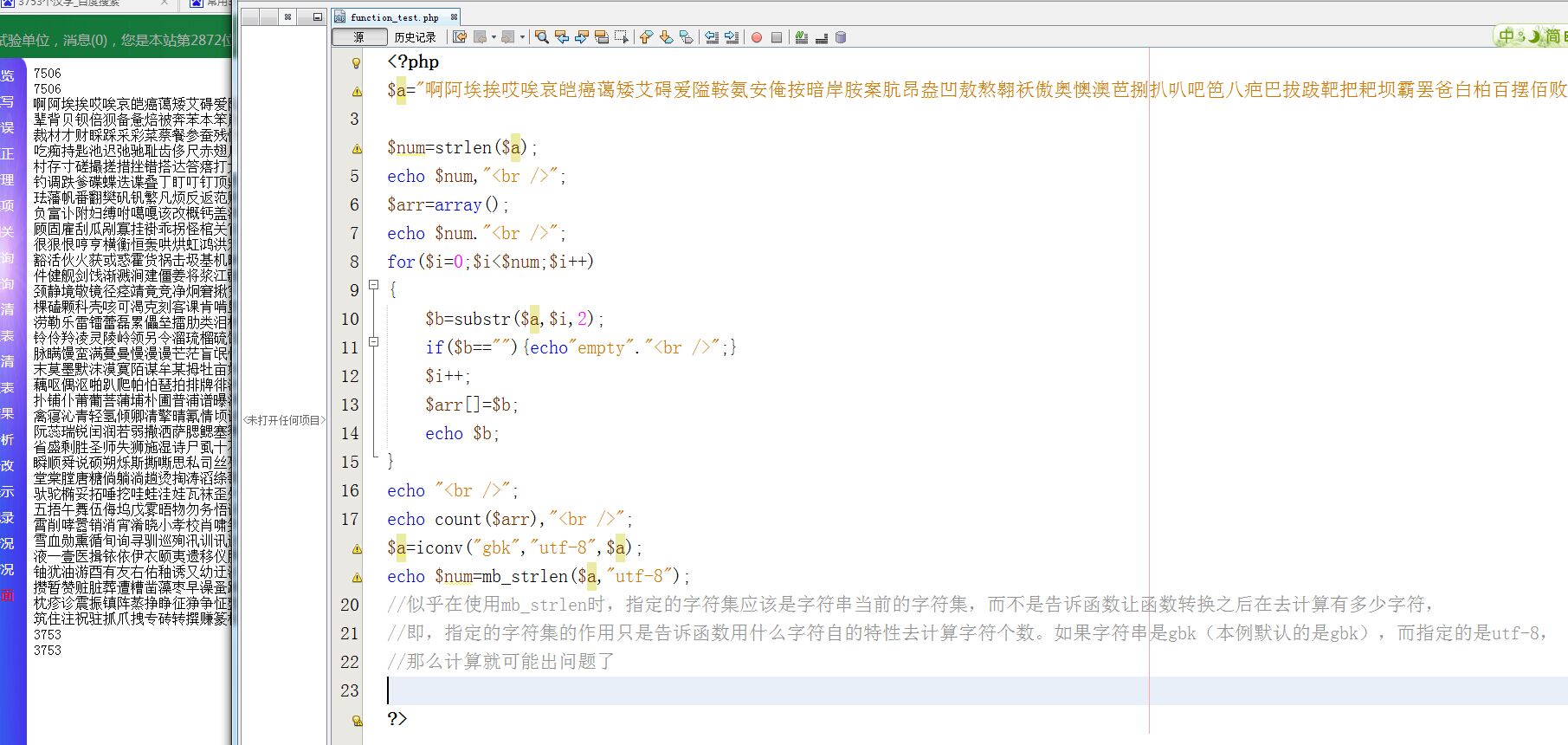
好吧,我已经知道怎么回事了,在使用 mb_strlen()时,指定的字符集应与字符串本身实际的字符集一致,才会得到正确的结果,因此,由于我的例子中,默认的是gbk,
而使用函数时指定的是utf-8来计算字符个数,当然是不对的了,因此在使用mb_strlen()前,利用iconv()函数进行转码即可,如下图所示