python scrapy框架使用时出现异常:由于目标计算机积极拒绝,无法连接
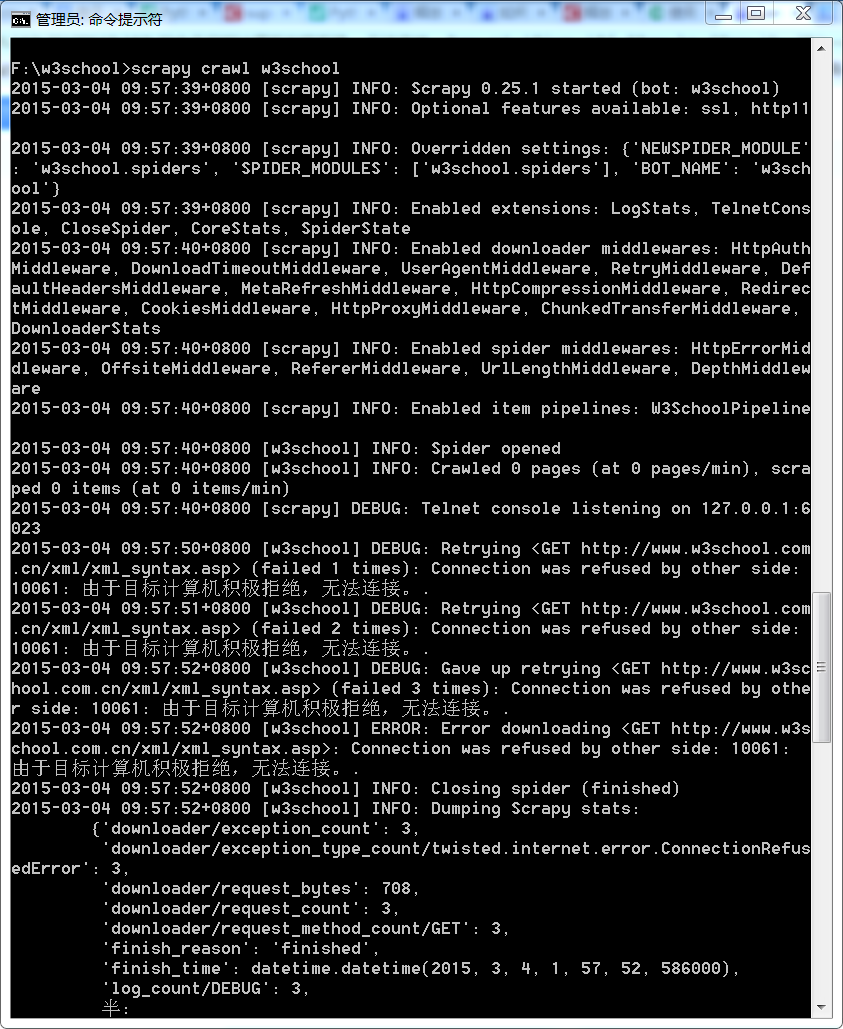
对方拒绝你访问,要么需要授权等,不允许你访问对应资源,或者发现你是爬虫,防火墙等拦截你的请求。
可是我用的是网上搜到的例子呀,http://scrapy-chs.readthedocs.org/zh_CN/latest/intro/tutorial.html#id2,
看了好多博客也是这样写的,应该蛮多人这样可以的吧。防火墙已经关闭。请问有什么方法可以解决这个问题吗?
我的问题已经解决了。我发现用python scrapy框架时默认访问的是IE浏览器,打开IE浏览器,发现直接输入百度的网址也无法链接。突然想起是以前使用代理服务器了。
点击alt键,出现【工具】->【Internet选项】->【连接】选项卡->【局域网设置】->去掉【代理服务器】下面的小对钩。重新用IE访问http://www.baidu.com/可以访问了。
再次运行之前的爬虫程序没有报错。希望遇到和我一样问题的人也能快速解决,研究了好久T_T
谢谢兄弟,帮我解决了!
我的解决方法是:
settings.py里,修改:
CONCURRENT_REQUESTS = 5 #之前是16
DOWNLOAD_DELAY = 1 #改之前是0.5
希望有帮助