通过算法大数据循环两两比较字符串,因为循环次数过多而导致程序过慢,如何解决?求救。。。
数据库有十万条数据,比较的规则是,第一条和第二条后面的所有数据进行比较,第二条和后第三条后面的所有数据进行比较,以此类推。。。比较所有的数据,所比较的数据是根据所选择的几个列的数据进行相应列的对比。这个过程非常慢,据说用哈希可以提高速度,但是针对我们这样的数据结构不知道如何构造哈希表,有没有大神知道怎么样解决这个问题,小弟在这里请教。。。。这个问题困扰了我很久都不能解决,求解决方案?
我们是在程序端(用winform)进行循环对比的,用了双循环。
以下是可能要比较的列: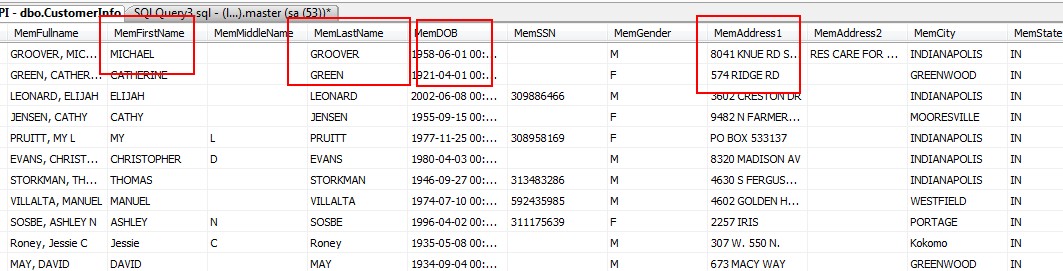
你只说了要比较,没有明确的目的很难给你提供思路,只能根据自己的需要做思路简化。
就是要找出相似度比较高的内容。你看我发的表结构以及可能要比较的列。
不需要hash,先排序,再比较就可以了。
如果是"相似度"比较,需要先分词,然后建立倒排索引或者字典树,然后比较。
建议:
首先,将所有行的MemFirstName和MemLastName做连接,采用hash算法映射到哈希表table1上;将剩余列做连接,再采用hash算法进行hash;该过程只需要扫描一遍,效率o(n);
其次,假设目标行为第i行,要与所有行进行对比,则先根据MemFirstName和MemLastName连接结果在table1中找近似的行;再通过第二个哈希表查找具体行。
如果需要根据日期排序之类的,就更简单的,可根据日期进行hash,大大缩小查找范围。