CUDA动态二维数组在核函数中应该如何引用?
不多说,直接上代码:
(1)头文件head_file.cuh
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
#include <iostream>
using namespace std;
//==========================复数类型==============================
//非零元值的数据类型
typedef double elem_type;
//逻辑值或者确切等于0或1
#define zero 0
#define one 1
#define ok 1
#define error 0
typedef struct
{
elem_type real;
elem_type image;
}complex;
const complex complex_zero = { zero, zero };
const complex complex_one = { one, zero };
const complex imu = { zero, one };
const complex tau = { one, zero };
__global__ void kernelFun(complex **d_array2D, size_t pitch, int R, int C);
(2)主函数main.cu
#include "head_file.cuh"
int main()
{
complex **CPU_ORIGN, **CPU_RET; //host端原数据、拷贝回数据
complex **GPU; //device端数据
int width = 3, height = 3; // 数组的宽度和高度
size_t size = sizeof(complex)*width; // 数据的宽度in bytes
int row, col;
// 申请内存空间, 并初始化
CPU_ORIGN = new complex*[height];
CPU_RET = new complex*[height];
for (row = 0; row < height; ++row)
{
CPU_ORIGN[row] = new complex[width];
CPU_RET[row] = new complex[width];
// 初始化数据
for (col = 0; col < width; ++col)
{
CPU_ORIGN[row][col] = {(elem_type)row,(elem_type)col};
CPU_RET[row][col] = {zero,zero};
}
}
//打印host端原数据
cout << "host端原数据:" << endl;
for (row = 0; row < height; ++row)
{
for (col = 0; col < width; ++col)
cout << CPU_ORIGN[row][col].real << " +" << CPU_ORIGN[row][col].image<<" ";
cout << endl;
}
cout << endl;
//打印host端原拷贝数据
cout << "host端原拷贝数据:" << endl;
for (row = 0; row < height; ++row)
{
for (col = 0; col < width; ++col)
cout << CPU_RET[row][col].real << " +" << CPU_RET[row][col].image << " ";
cout << endl;
}
cout << endl;
size_t pitch;
cudaMallocPitch((void**)&GPU, &pitch, size, height);
cudaMemset2D(GPU, pitch, 0, size, height);
// 将host端原数据拷贝到device端
cudaMemcpy2D(GPU, pitch, CPU_ORIGN, size, size, height, cudaMemcpyHostToDevice);
int blocksize = 1;
dim3 block(blocksize);
cout << "线程块的大小block.x:" << block.x << endl;
int blocknum = 1;
dim3 grid(blocknum);
cout << "线程块的个数grid.x:" << grid.x << endl << endl;
cudaDeviceSynchronize();
kernelFun<<<grid, block>>>(GPU, pitch, height, width);
cudaDeviceSynchronize();
// 将device端数据拷贝到host端返回数据
cudaMemcpy2D(CPU_RET, size, GPU, pitch, size, height, cudaMemcpyDeviceToHost);
//打印host端最终数据
cout << endl << "host端最终数据:" << endl;
for (row = 0; row < height; ++row)
{
for (col = 0; col < width; ++col)
cout << CPU_RET[row][col].real << " +" << CPU_RET[row][col].image << " ";
cout << endl;
}
cout << endl;
// 释放内存和显存空间
for (int i = 0; i < row; i++)
delete[]CPU_ORIGN[i];
delete[]CPU_ORIGN;
for (int i = 0; i < row; i++)
delete[]CPU_RET[i];
delete[]CPU_RET;
cudaFree(GPU);
system("pause");
return ok;
}
(3)核函数kernelFun.cu
__global__ void kernelFun(complex **d_array2D, size_t pitch, int R, int C)
{
printf("R的值:%d\n", R);
printf("C的值:%d\n\n", C);
printf("块大小blockDim.x:%d\n", blockDim.x);
printf("块代号blockIdx.x:%d\n", blockIdx.x);
printf("块内线程号threadIdx.x:%d\n\n", threadIdx.x);
for (int i = 0; i<R; i++)
{
for (int j = 0; j<C; j++)
{
printf("d_array2D[%d][%d]的值:%15.6f+%15.6f\n", i+1,j+1,d_array2D[i][j].real,\
d_array2D[i][j].image);
d_array2D[i][j] = {2, 0};
}
}
}
目前得到的结果是: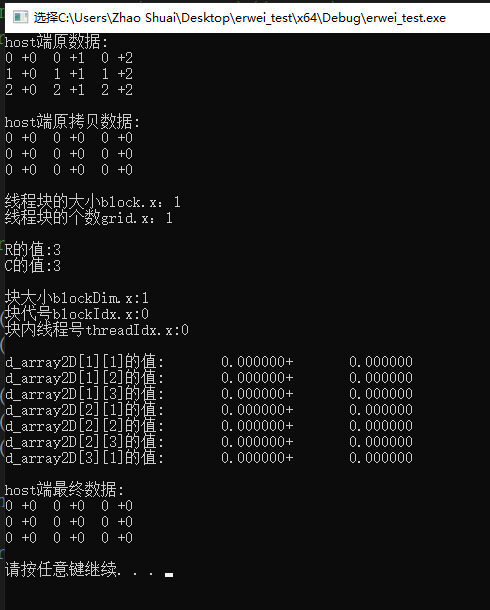
问题描述:
(1)为什么核函数中printf输出的结果全是0?
(2)如果注释掉核函数,最终的结果又正常了,这表明传入/传出gpu是正常的?
(3)在核函数中,到底应该怎样访问二维动态数组的某个元素a[i][j]呢?