python的pandas库导入Excel后为何数字类型数据变为时间类型数据
Excel表格如图: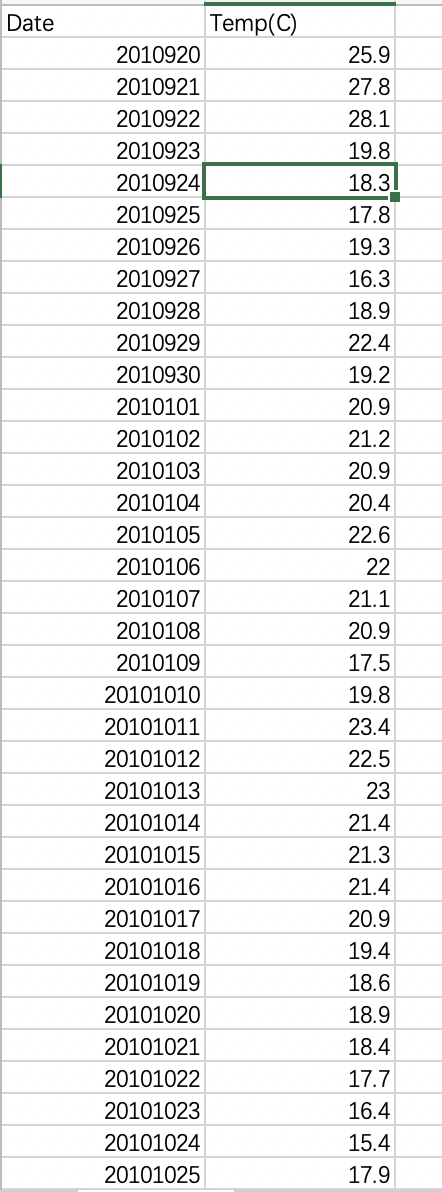
想要做时间序列数据的线性回归,于是导入pd.read_excel:
index_col=0 是第一列时间作为索引,然后想将气温一列数据类型抓换为float类型,出现报错:
float() argument must be a string or a number, not 'datetime.datetime'
如果不转float序列,后期计算自相关函数却又报错:
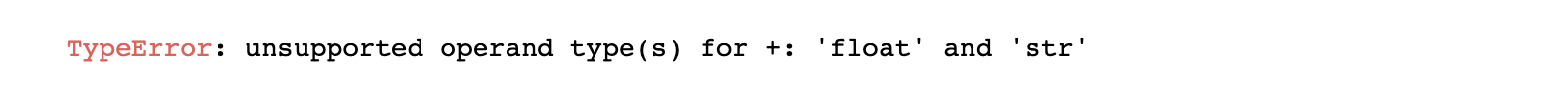
unsupported operand type(s) for +: 'float' and 'str'
求解是excel数据需要更改吗
这是excel文件本身的问题,在输入的时候,这一类被自动识别为日期列了
在excel文件里设置下这一列的格式,再导入
dtype应该是:{列名:类型}
dtype= {'Temp(C)': float }
你看文档注释就明白了
>>> pd.read_excel('tmp.xlsx', index_col=0,
... dtype={'Name': str, 'Value': float}) # doctest: +SKIP
Name Value
0 string1 1.0
1 string2 2.0
2 #Comment 3.0