求助:python爬取图片,怎么取出标签里的src内容?
from bs4 import BeautifulSoup
import requests
import os
import lxml
import parsel
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.83 Safari/537.36'
}
url = 'https://www.archdaily.com/946565/higashi-sanchome-toilet-nao-tamura/5f4790beb35765c1ca0000ea-higashi-sanchome-toilet-nao-tamura-photo'
result = requests.get(url, headers= headers)
parse = parsel.Selector(result.text)
targetCode = parse.xpath('/html/body/div[1]/div[1]/div[1]/div/div/div[1]/figure/img')
print(targetCode)
返回的结果
[<Selector xpath='/html/body/div[1]/div[1]/div[1]/div/div/div[1]/figure/img' data='<img class="afd-gal-img js-gal-img" i...'>]
我需要的内容是img标签里的src或是data-largesrc图片地址(两者内容好像一样),试过print(targetCode.extract_first().encode('utf-8'))
但是返回img内容只有一半
b'<img class="afd-gal-img js-gal-img" id="5f4790beb35765c1ca0000ea-higashi-sanchome-toilet-nao-tamura-photo" alt="Higashi Sanchome Toilet / Nao Tamura,\xc2\xa9 Satoshi Nagare, Courtesy of The Nippon Foundation" style="transform-origin: 50% 50%;">'
前面有个b不知道是什么东西,然后也不是我要的,用.extract()也不行,折腾好久了,麻烦帮忙解答下,谢谢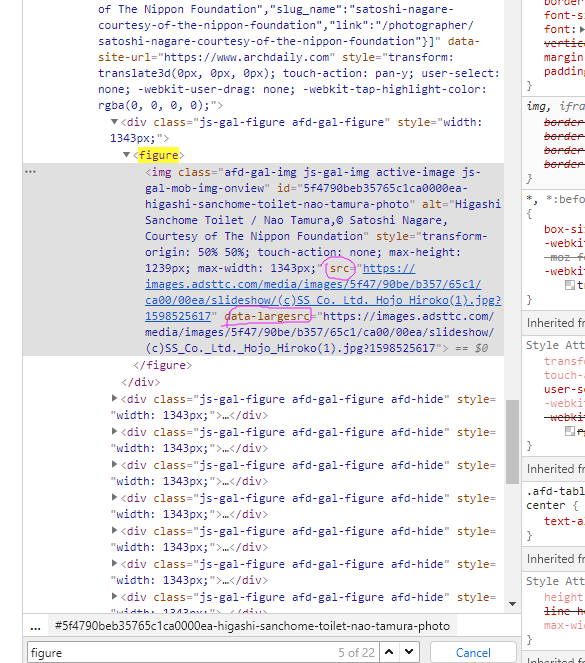
源码中有包含所有图片url的json对象
因此可以使用BeautifulSoup找到该对象,然后利用json模块读取对象中的所有url,爬取的结果展示如下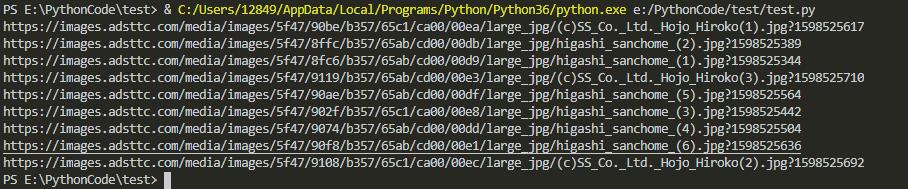
源码如下
from bs4 import BeautifulSoup
import requests
import os
import lxml
import json
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.83 Safari/537.36'
}
url = 'https://www.archdaily.com/946565/higashi-sanchome-toilet-nao-tamura/5f4790beb35765c1ca0000ea-higashi-sanchome-toilet-nao-tamura-photo'
result = requests.get(url, headers= headers)
soup = BeautifulSoup(result.content,'lxml')
json_data = soup.find('div',attrs={'id':'gallery-items'})
figures = json.loads(json_data.get('data-images'))
for figure in figures:
print(figure['url_large'])
我在本地运行了楼主的代码 应该没有问题 至于img只有一半也是正常的
楼主需要明白一件事:爬虫爬取的是浏览器右键源代码查看的内容 不是开发工具看到的内容 源代码里img就是没有src的
如果想要获取src需要改用selenium等操作浏览器可以拿到 或者分析src看看是在哪个JS或者请求出现的 直接请求那个文件就行了
使用@src,extract提取
targetCode = parse.xpath('/html/body/div[1]/div[1]/div[1]/div/div/div[1]/figure/img/@src')
print(targetCode.extract())
https://blog.csdn.net/ayouleyang/article/details/97958346
b表示这是一个二进制串
targetCode = parse.xpath('/html/body/div[1]/div[1]/div[1]/div/div/div[1]/figure/img/@src')
print(targetCode.extract_first().encode('utf-8'))
这样看看
看了一下,这个网页在请求的时候就已经有了这个图片,路径并非动态加载的,把你要拉的图片名字复制,比如你截图里的SS_Co._Ltd._Hojo_Hiroko,在Element页签里搜索就行了,也可以本地将第一时间拿到的内容保存为文本文档,在里面搜索,搜不到就可以判定是异步加载的内容。特定位置图片的话关注property/id/class/name等,确认想匹配网页元素里的哪一块内容。og:image和twitter:image是大图路径,thumbnail里是中图(也就是你看的figure里存放的路径)。确认了这些东西之后,就简单了。。在网页元素里直接正则匹配出自己想要的内容就好,先匹配对应property/id/class/name中间内容,然后匹配content/src就好。下面附图
做东西思路最重要,条条大路通罗马。。。
如果是异步加载的内容,通过NetWork看具体哪条请求获取到异步内容,后续就是在Header里看具体怎么请求的了。
编辑一下,插个图,用评论中的正则匹配的结果如下
import re
imgurl = re.search('data-img="(.*?)"',result.text).group(1)
imgurl = imgurl.replace('newsletter','large_jpg')
不好意思,没看到你要的是largesrc的内容
我研究了下,这个data-img取出来的是【newsletter】
https://images.adsttc.com/media/images/5f47/90be/b357/65c1/ca00/00ea/newsletter/(c)SS_Co._Ltd._Hojo_Hiroko(1).jpg?1598525617
SS_Co._Ltd._Hojo_Hiroko(1).jpg?1598525617){kind=link}
然后largesrc里面是【slideshow】,其他的都是相同的
https://images.adsttc.com/media/images/5f47/90be/b357/65c1/ca00/00ea/slideshow/(c)SS_Co._Ltd._Hojo_Hiroko(1).jpg?1598525617
SS_Co._Ltd._Hojo_Hiroko(1).jpg?1598525617){kind=link}
而largesrc这个在requests里面取出来的时候是找不到的,目前是可以通过把newsletter替换成slideshow来获取取大图片
或者换成【large_jpg】也是可以的。