求助交叉熵的定义中,“按照真实分布p来衡量识别一个样本的所需要的编码长度”是什么意思?
如题,求助~我看到“https://blog.csdn.net/FrankieHello/article/details/80613952”中说:
现有关于样本集的2个概率分布p和q,其中p为真实分布,q非真实分布。按照真实分布p来衡量识别一个样本的所需要的编码长度的期望(即平均编码长度)为:
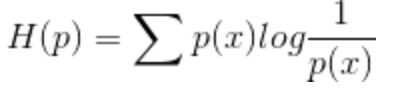
怎么分布还分真实分布和非真实分布呢? 还有就是,“按照真实分布p来衡量识别一个样本”是什么意思?分布就是分布呗,还有“按照分布来识别样本”的作用?很奇怪呀~
p表示真实分布,q表示p的拟合分布(所谓非真实分布只是一种不规范的说法)
识别一个样本的所需要的编码长度,在分类算法中你可以理解为log以2为底,分类个数 bit。比如说对手写数字0~9编码,至少需要4bit
p为真实分布,q非真实分布
其实就是P为标签,Q为网络预测输出结果,
拟合分布就是由于网络内部参数在未训练好时,输出并不是我们想要的,而我们使用交叉熵就是评定标签和网络输出的分布之间的差距,之后采用反向传播算法,使得网络内部参数更新,使下一次网络输出更加贴近标签的分布。