关于爬虫获取接口数据的问题
http://jishukong.com/statistics?roleSort=&sortBy=general.winPercent&order=descend
这是网址,我在爬取的时候发现它的数据是通过js来获取的,但是我在控制台并没有发现它获取数据的地址。请问这一类的数据应该通过怎样的方式来获取?
您好:
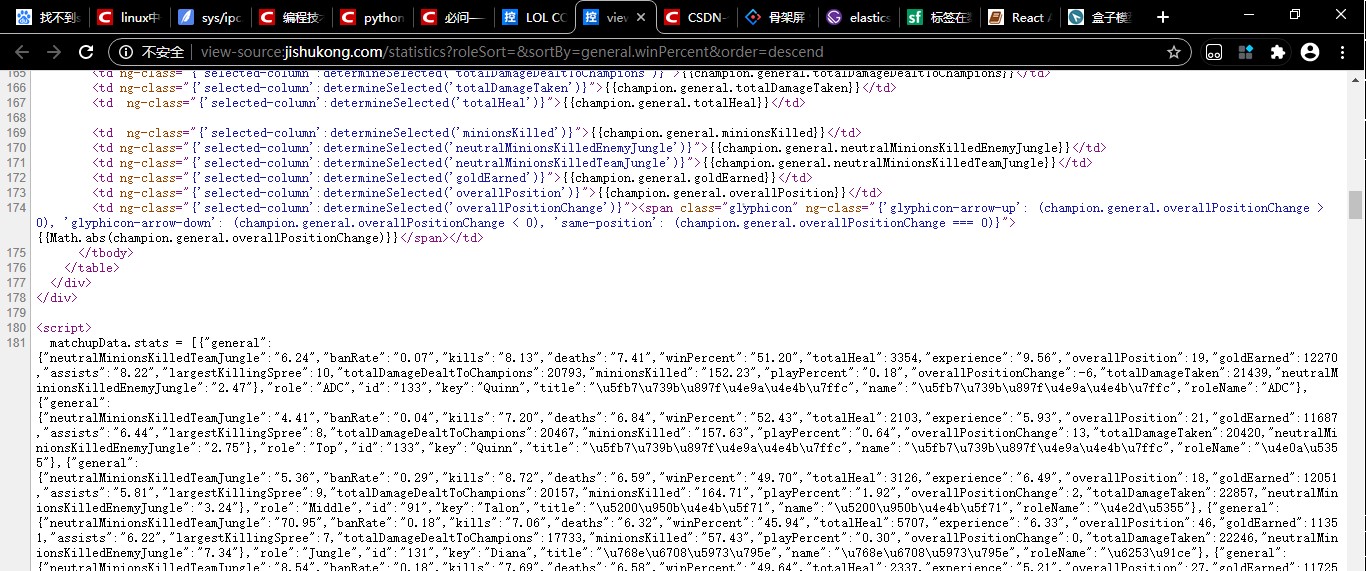
对于这个网页,他的数据应该就在你发的url里,我在源码的第181行看到了疑似数据的内容
应该是用json写在了<script>标签里
import requests
import json
from bs4 import BeautifulSoup
url=''#这儿输入地址
html=requests.get(url)
bs=BeautifulSoup(html.text, "html.parser")
scripts=bs.find_all('script')
for script in scripts:
string = script.string
if string:
content= string.strip()
if content.find('matchupData.stats')!=-1:
content= content.split('=')[1].strip(';')
decodedContent= content.encode('utf-8').decode('unicode_escape')
data= json.loads(decodedContent)
print(data)
break