有个爬虫需求不知道哪位仁兄可以做?
1.现在有个爬虫需求,需要爬取全国个高校的招聘数据,数据包括招聘岗位,人数,专业要求,岗位要求、学历要求等。因为是学校抓取数据做分析,所以在价钱上不会太高大概两千左右。问题难点在于高校的网站过多,不能很好的统一网站源,第二个在于各省市人社厅也会有高校的招聘信息,进一步提升了难度。招聘信息类似于这种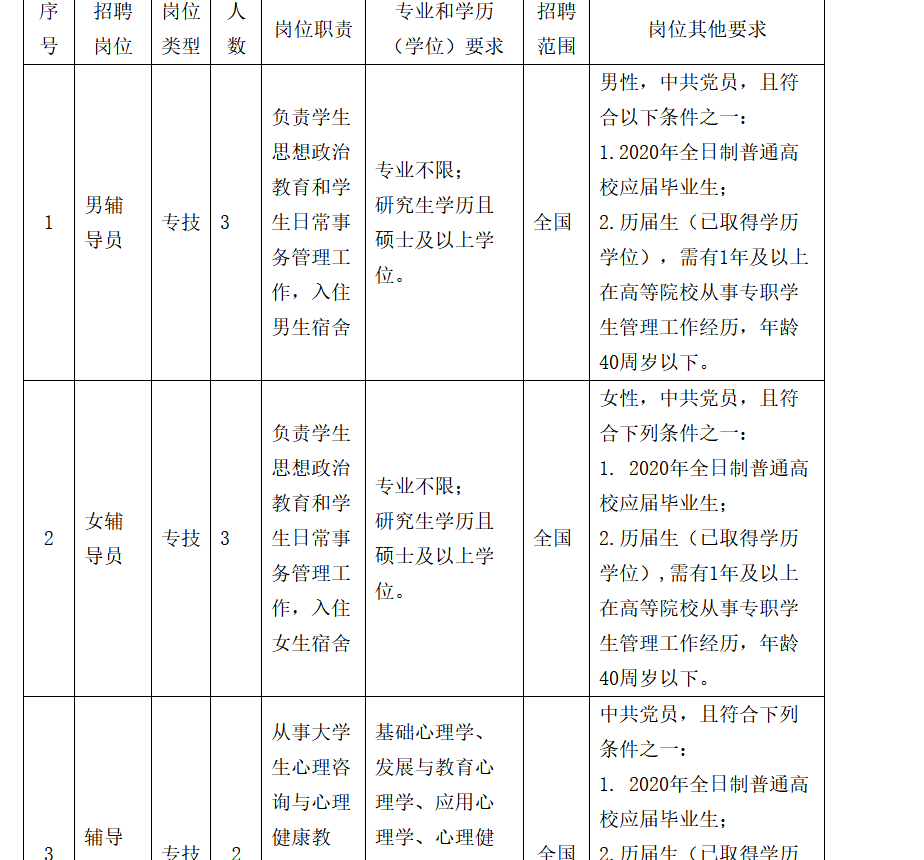 。有些信息隐藏在网页的文档连接中,需要下载并读取信息
。有些信息隐藏在网页的文档连接中,需要下载并读取信息
这个·是需要你把要爬取的网站列出来吧,而且网站不一样相应的爬取也不一样吧,这个应该不是难,就是麻烦
如果是一次性的,做个统一的excel模板,找10个人,分工同时收集,一人一天一百,两天时间就差不多了
代码应该不难,就是很费事
1、毕竟每个网站的格式是不一样的,爬取的代码需要和每个网站对应
2、下载的文档如果是word格式或者图片无法识别的,只能是excel
3、excel格式如果发生改变下次爬取还需要重新修改代码