在 python scrapy爬虫框架:response.xpath()的返回值是[ ],这个怎么解决?
我在用xpath helper插件都可以检索到:
但是运行时的显示值是None或者[]。
这是scrapy shell的解析: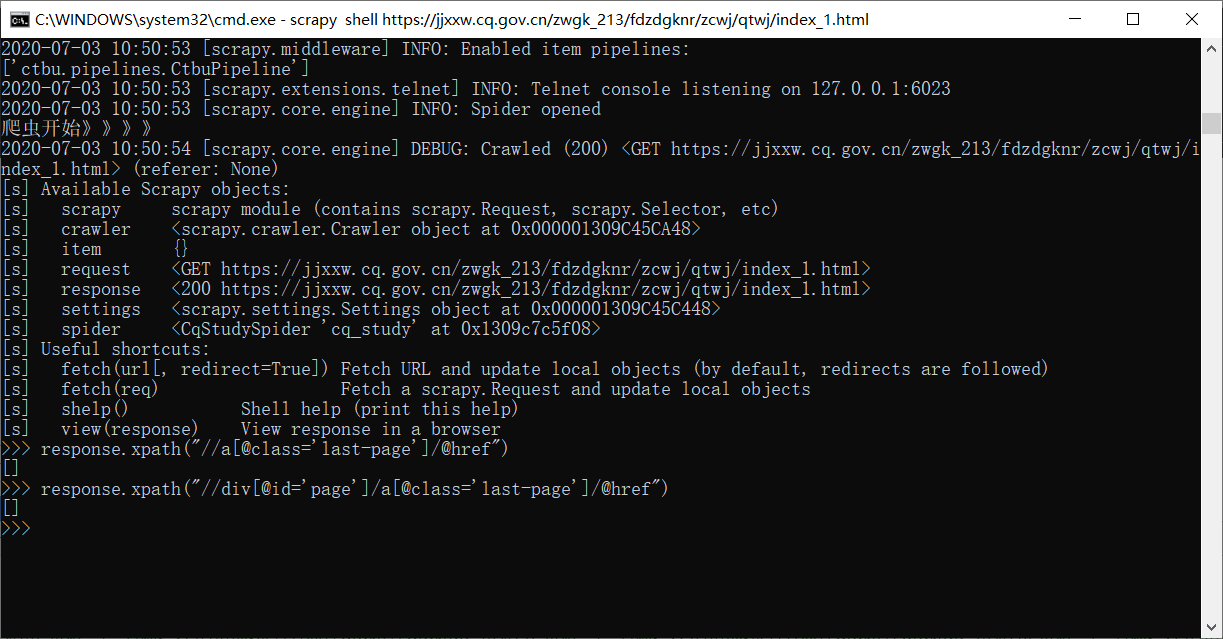
考虑网页的内容使用了ajax,使用右键-》查看网页源代码,看是否仍然能获得指定的内容
你可以先看下你response的网页源代码和你浏览器的是不是一样的,先确定有没有在看xpath语法
你可以在浏览器里使用f12进行分析,选择network 里面的xhr里找找 找一个ajax进行获取 他的名字应该就包含你要的页数。
可以加个判断吧,if 返回为[]就continue