这是一个关于计算机组成原理的问题
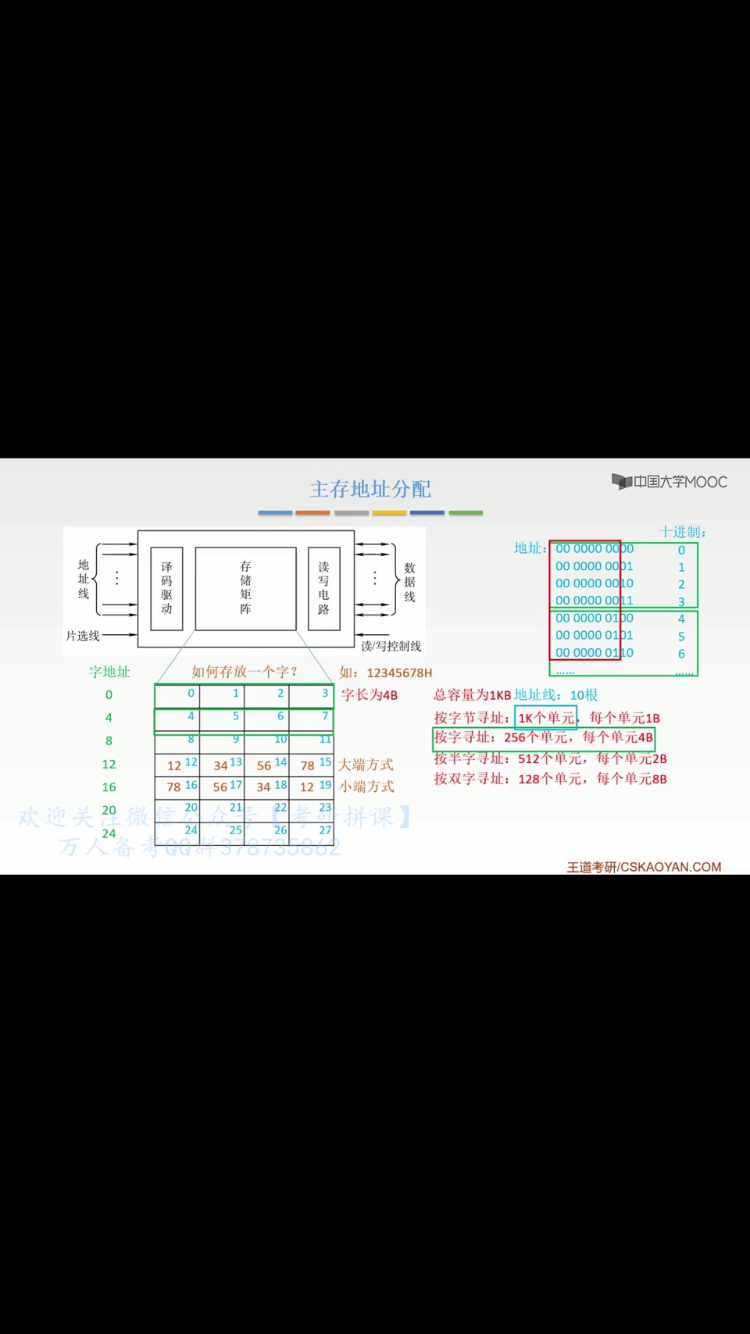
我原本以为按字寻址,是以字为单位寻址,每次寻址都是找的字。假如机器字长4字节,那么每个地址指向4字节。但是看这个图,我发现按字寻址和按字节寻址一样。作用都是找字节,只不过按字寻址更麻烦,要搞个组号,组内编码,如上图。
总体上看,按字寻址更麻烦,需要搞个组号,且作用也是按字节寻址。那么整个按字寻址还有什么意义呢?
优点:相同的地址范围可以表示更大的存储空间。也就是意味着节约了地址。
访问连续大量的数据更有效率。
缺点:访问零碎不连续数据效率更低,更消耗cpu
按字寻址和按字节寻址虽然都是“找的字”,但是按字寻址可一次读取出多个字节,这对有些情况特别是多字节的数据的存储会非常方便。
组号和组内编码只是对整个地址按的进行的划分,通过组号和组内编码这种“更麻烦”的方式一次读取多个字节数据,麻烦的同时,收益也是很大的。
通过组号确定字地址,组内号找字节 麻烦但是方便。