用scrapy有数据缺失,求助大佬!感谢
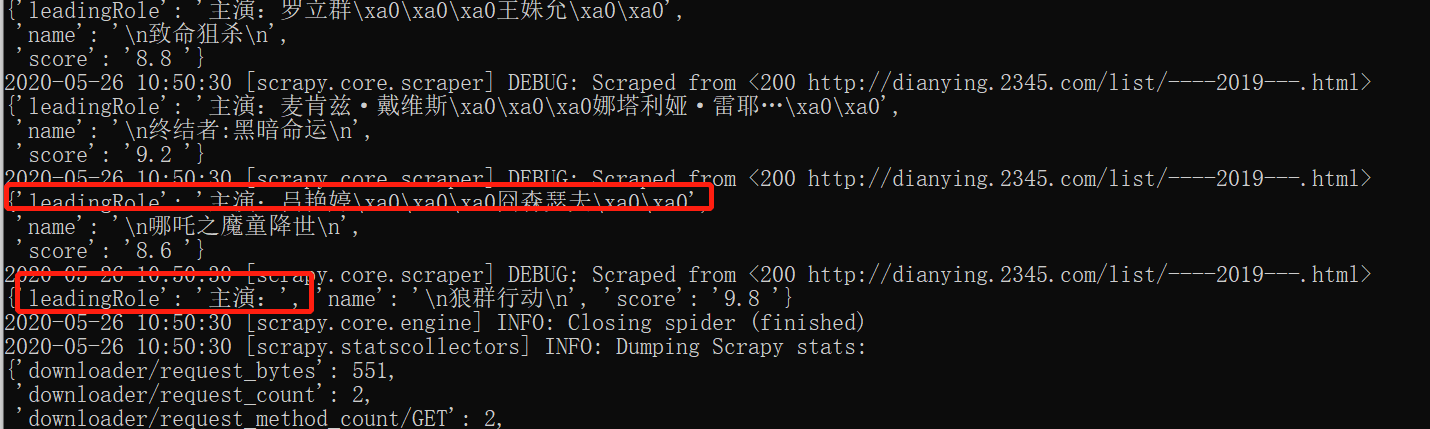
爬取代码如下
import scrapy
from bs4 import BeautifulSoup
from dianying.items import DianyingItem
import re
class DianyingspiderSpider(scrapy.Spider):
name = 'dianyingSpider'
allowed_domains = ['http://dianying.2345.com/list/----2019---.html']
start_urls = ['http://dianying.2345.com/list/----2019---.html']
#start_urls =[]
#for i in range(1,3):
# start_urls.append('http://dianying.2345.com/list/----2019---'+str(i)+'.html')
def parse(self, response):
soup = BeautifulSoup(response.text,'lxml')
anchorTag = soup.find( 'ul',attrs = {'class':"v_picTxt pic180_240 clearfix"})
tags = anchorTag.find_all('li',attrs={'media':re.compile('\d{6}')}) #找到不同电影的不同代码
items = []
for tag in tags:
item = DianyingItem()
item['name']= tag.find('span',attrs={'class':'sTit'}).get_text() #爬取电影名
item['score'] = tag.find('span',attrs={'class':'pRightBottom'}).get_text().replace('分',' ') #爬取评分
item['leadingRole'] = tag.find('span',attrs={'class':'sDes'}).get_text() #爬取主演
items.append(item)
return items