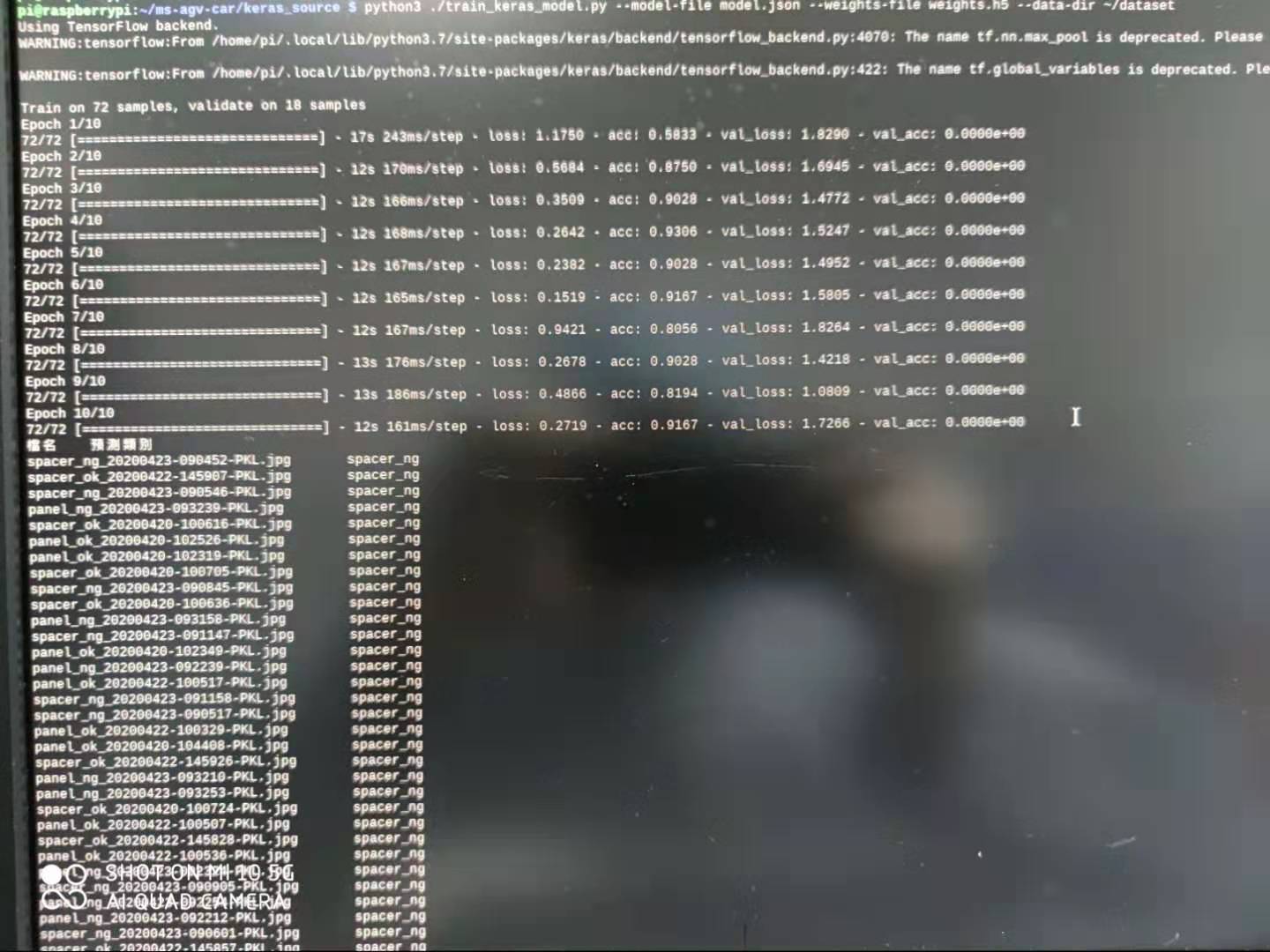
1.我在树莓派4B用keras训练模型时一直失败。图片说明
2.在树莓派3B 上python3.5.3训练就没问题!
3.这是我在网上找的一个叫 ms-agv-car-master 的图像识别包。这是地址:https://github.com/jerry73204/ms-agv-car
import os
import glob
import argparse
import cv2
import numpy as np
from keras.models import Model
from keras.layers import Dense, Activation, MaxPool2D, Conv2D, Flatten, Dropout, Input, BatchNormalization, Add
from keras.optimizers import Adam
from keras.utils import multi_gpu_model, plot_model
# Keras 內建模型
# https://keras.io/applications
from keras.applications.vgg16 import VGG16
from keras.applications.vgg19 import VGG19
from keras.applications.resnet50 import ResNet50
from keras.applications.densenet import DenseNet121
from keras.applications.mobilenetv2 import MobileNetV2
def custom_model(input_shape, n_classes):
def conv_block(x, filters):
x = BatchNormalization() (x)
x = Conv2D(filters, (3, 3), activation='relu', padding='same') (x)
x = BatchNormalization() (x)
shortcut = x
x = Conv2D(filters, (3, 3), activation='relu', padding='same') (x)
x = Add() ([x, shortcut])
x = MaxPool2D((2, 2), strides=(2, 2)) (x)
return x
input_tensor = Input(shape=input_shape)
x = conv_block(input_tensor, 32)
x = conv_block(x, 64)
x = conv_block(x, 128)
x = conv_block(x, 256)
x = conv_block(x, 512)
x = Flatten() (x)
x = BatchNormalization() (x)
x = Dense(512, activation='relu') (x)
x = Dense(512, activation='relu') (x)
output_layer = Dense(n_classes, activation='softmax') (x)
inputs = [input_tensor]
model = Model(inputs, output_layer)
return model
def main():
# 定義程式參數
arg_parser = argparse.ArgumentParser(description='模型訓練範例')
arg_parser.add_argument(
'--model-file',
required=True,
help='模型描述檔',
)
arg_parser.add_argument(
'--weights-file',
required=True,
help='模型參數檔案',
)
arg_parser.add_argument(
'--data-dir',
required=True,
help='資料目錄',
)
arg_parser.add_argument(
'--model-type',
choices=('VGG16', 'VGG19', 'ResNet50', 'DenseNet121', 'MobileNetV2', 'custom'),
default='custom',
help='選擇模型類別',
)
arg_parser.add_argument(
'--epochs',
type=int,
default=32,
help='訓練回合數',
)
arg_parser.add_argument(
'--output-file',
default='-',
help='預測輸出檔案',
)
arg_parser.add_argument(
'--input-width',
type=int,
default=48,
help='模型輸入寬度',
)
arg_parser.add_argument(
'--input-height',
type=int,
default=48,
help='模型輸入高度',
)
arg_parser.add_argument(
'--load-weights',
action='store_true',
help='從 --weights-file 指定的檔案載入模型參數',
)
arg_parser.add_argument(
'--num-gpu',
type=int,
default=1,
help='使用的GPU數量,預設為1',
)
arg_parser.add_argument(
'--plot-model',
help='繪製模型架構圖',
)
args = arg_parser.parse_args()
# 資料參數
input_height = args.input_height
input_width = args.input_width
input_channel = 3
input_shape = (input_height, input_width, input_channel)
n_classes = 4
# 建立模型
if args.model_type == 'VGG16':
input_tensor = Input(shape=input_shape)
model = VGG16(
input_shape=input_shape,
classes=n_classes,
weights=None,
input_tensor=input_tensor,
)
elif args.model_type == 'VGG19':
input_tensor = Input(shape=input_shape)
model = VGG19(
input_shape=input_shape,
classes=n_classes,
weights=None,
input_tensor=input_tensor,
)
elif args.model_type == 'ResNet50':
input_tensor = Input(shape=input_shape)
model = ResNet50(
input_shape=input_shape,
classes=n_classes,
weights=None,
input_tensor=input_tensor,
)
elif args.model_type == 'DenseNet121':
input_tensor = Input(shape=input_shape)
model = DenseNet121(
input_shape=input_shape,
classes=n_classes,
weights=None,
input_tensor=input_tensor,
)
elif args.model_type == 'MobileNetV2':
input_tensor = Input(shape=input_shape)
model = MobileNetV2(
input_shape=input_shape,
classes=n_classes,
weights=None,
input_tensor=input_tensor,
)
elif args.model_type == 'custom':
model = custom_model(input_shape, n_classes)
if args.num_gpu > 1:
model = multi_gpu_model(model, gpus=args.num_gpu)
if args.plot_model is not None:
plot_model(model, to_file=args.plot_model)
adam = Adam()
model.compile(
optimizer=adam,
loss='categorical_crossentropy',
metrics=['acc'],
)
# 搜尋所有圖檔
match_left = os.path.join(args.data_dir, 'left', '*.jpg')
paths_left = glob.glob(match_left)
match_right = os.path.join(args.data_dir, 'right', '*.jpg')
paths_right = glob.glob(match_right)
match_stop = os.path.join(args.data_dir, 'stop', '*.jpg')
paths_stop = glob.glob(match_stop)
match_other = os.path.join(args.data_dir, 'other', '*.jpg')
paths_other = glob.glob(match_other)
match_test = os.path.join(args.data_dir, 'test', '*.jpg')
paths_test = glob.glob(match_test)
n_train = len(paths_left) + len(paths_right) + len(paths_stop) + len(paths_other)
n_test = len(paths_test)
# 初始化資料集矩陣
trainset = np.zeros(
shape=(n_train, input_height, input_width, input_channel),
dtype='float32',
)
label = np.zeros(
shape=(n_train, n_classes),
dtype='float32',
)
testset = np.zeros(
shape=(n_test, input_height, input_width, input_channel),
dtype='float32',
)
# 讀取圖片到資料集
paths_train = paths_left + paths_right + paths_stop + paths_other
for ind, path in enumerate(paths_train):
image = cv2.imread(path)
resized_image = cv2.resize(image, (input_width, input_height))
trainset[ind] = resized_image
for ind, path in enumerate(paths_test):
image = cv2.imread(path)
resized_image = cv2.resize(image, (input_width, input_height))
testset[ind] = resized_image
# 設定訓練集的標記
n_left = len(paths_left)
n_right = len(paths_right)
n_stop = len(paths_stop)
n_other = len(paths_other)
begin_ind = 0
end_ind = n_left
label[begin_ind:end_ind, 0] = 1.0
begin_ind = n_left
end_ind = n_left + n_right
label[begin_ind:end_ind, 1] = 1.0
begin_ind = n_left + n_right
end_ind = n_left + n_right + n_stop
label[begin_ind:end_ind, 2] = 1.0
begin_ind = n_left + n_right + n_stop
end_ind = n_left + n_right + n_stop + n_other
label[begin_ind:end_ind, 3] = 1.0
# 正規化數值到 0~1 之間
trainset = trainset / 255.0
testset = testset / 255.0
# 載入模型參數
if args.load_weights:
model.load_weights(args.weights_file)
# 訓練模型
if args.epochs > 0:
model.fit(
trainset,
label,
epochs=args.epochs,
validation_split=0.2,
# batch_size=64,
)
# 儲存模型架構及參數
model_desc = model.to_json()
with open(args.model_file, 'w') as file_model:
file_model.write(model_desc)
model.save_weights(args.weights_file)
# 執行預測
if testset.shape[0] != 0:
result_onehot = model.predict(testset)
result_sparse = np.argmax(result_onehot, axis=1)
else:
result_sparse = list()
# 印出預測結果
if args.output_file == '-':
print('檔名\t預測類別')
for path, label_id in zip(paths_test, result_sparse):
filename = os.path.basename(path)
if label_id == 0:
label_name = 'left'
elif label_id == 1:
label_name = 'right'
elif label_id == 2:
label_name = 'stop'
elif label_id == 3:
label_name = 'other'
print('%s\t%s' % (filename, label_name))
else:
with open(args.output_file, 'w') as file_out:
file_out.write('檔名\t預測類別\n')
for path, label_id in zip(paths_test, result_sparse):
filename = os.path.basename(path)
if label_id == 0:
label_name = 'left'
elif label_id == 1:
label_name = 'right'
elif label_id == 2:
label_name = 'stop'
elif label_id == 3:
label_name = 'other'
file_out.write('%s\t%s\n' % (filename, label_name))
if __name__ == '__main__':
main()
{kind=link}