mysql left join 查询问题
select count(1) from work_form_3 w1 left join work_form_3 w2 on w1.LOT_NO=w2.LOT_NO
这个查询多次,平均耗时800ms,最高不超过850ms,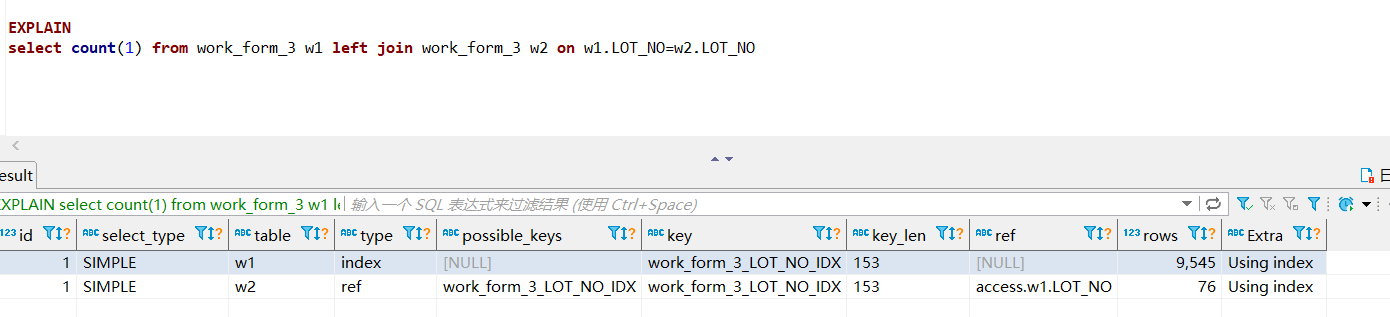
select count(1) from work_form_3 w1 left join work_form_3 w2 on w1.REEL_NO_1=w2.REEL_NO_1
这个查询多次,平均耗时400ms,最高不超过450ms,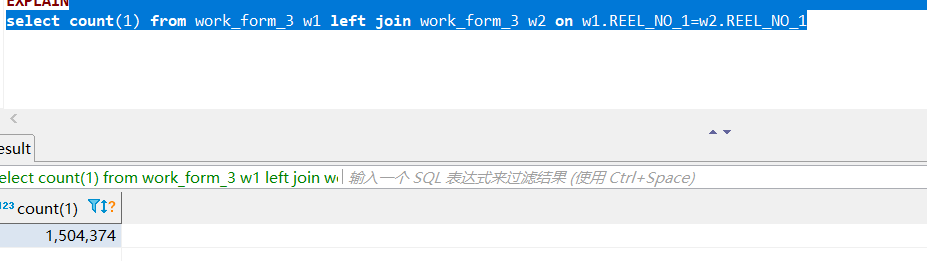
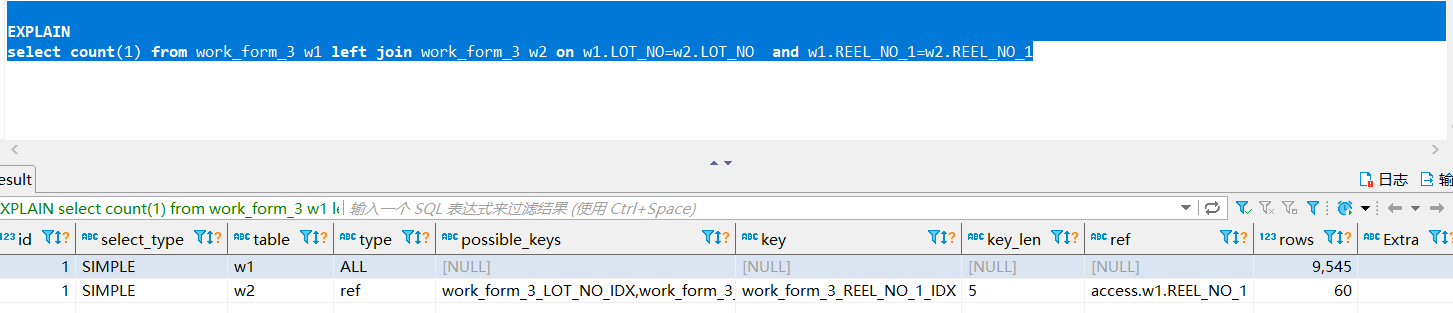
问题来了,下面这条sql查询平均耗时3.8s,最高可到4.3s,不应该是使用索引,查询时间应该在1s以下吧?求各位大佬解答,left join on后面的条件是什么情况?用自己连自己就是为了确定不是由于字段字符引起索引失效的问题。
select count(1) from work_form_3 w1 left join work_form_3 w2 on w1.LOT_NO=w2.LOT_NO and w1.REEL_NO_1=w2.REEL_NO_1
https://blog.csdn.net/luka2008/article/details/47006259
因为左连接是左边查所有,也就是a表查所有,既然是查所有,那么就用不到索引,除非你有where a.a=xxx
第一 第二条差不多,左表全扫描,右表走索引,因为主表要展示全部所以全扫描 会更快写,右表走索引,证明mysql认为索引快,因此我盲猜右表数据比左表多,或者两表数据都不是很大,第三条慢是条件多,增加了负担,不是所有条件都走索引的,可能第一个走索引第二个就全表扫了,所以慢