做了python爬取豆瓣电影程序,但是一直出错
import requests
import json
if __name__ == "__main__":
url = 'https://movie.douban.com/j/search_subjects' # 指定URL
params = {
'type':'movie', 'tag':'%E5%96%9C%E5%89%A7','sort':'recommend', 'page_limit':'20',
'page_start':'0'
}
headers = {
'User Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3947.100 Safari/537.36'
} # UA伪装
response = requests.get(url=url, params=params, headers=headers) # get请求
# 获取响应数据
list_data = response.json()
fp = open('./douban.json', 'w', encoding='utf-8')
json.dump(list_data, fp=fp, ensure_ascii=False)
print('保存成功!!!')
我也爬过豆瓣,应该是你直接用 response.json 这个用法不对,应该将 response.text 转成 JSON:
import requests
import json
url="https://movie.douban.com/j/search_subjects?type=movie&tag=%E7%83%AD%E9%97%A8&page_limit=50&page_start=0"
headers = {
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.122 Safari/537.36",
"Referer":"https://movie.douban.com/"
}
response = requests.get(url,headers=headers)
# loads as json
result = json.loads(response.text)
# get subjects
subjects = result['subjects']
def itemInfo(item):
info = '{},{},{},{}\r\n'.format(item['title'], item['rate'],item['url'],item['cover_x'])
return info
# write to file
f1 = open('E:/film.log','w',encoding='utf-8')
for item in subjects:
print(itemInfo(item))
f1.write(itemInfo(item))
结果: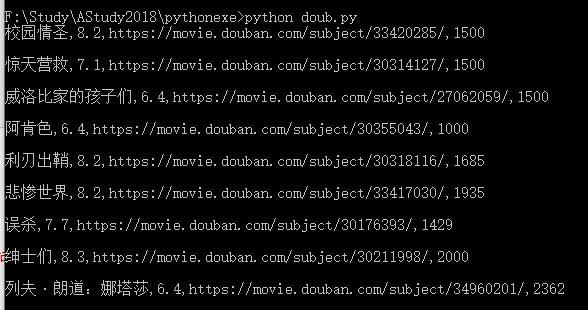
楼主你的这个问题解决了吗?