Pasdas eval()和DataFrame.eval()真的可以提升性能?
Pasdas eval()和DataFrame.eval()真的可以提升性能?
测试代码:
nrows,ncols = 100000,100
rng = np.random.RandomState(42)
df1,df2,df3,df4 = (pd.DataFrame(rng.rand(nrows,ncols)) for i in range(4))
%timeit (df1<df3) & (df2<1) | (df3<df4)
%timeit pd.eval('(df1<df3) & (df2<1) | (df3<df4)')
测试结果:
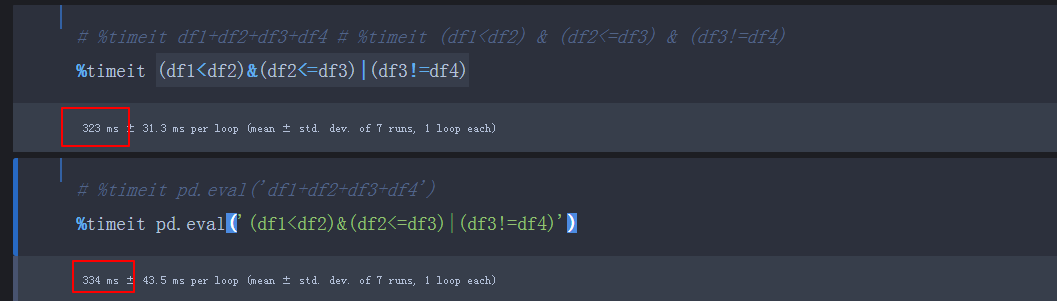
对比下,运行时间并没有像网上那样提升那没多?这是因为电脑配置导致?
都是几百毫秒,不能看出差距,要加大数据规模,或者多运行几次
测试Pasdas.eval 的确可以提升效率 , 但是有前提 , 在多行且多列(行列数较为均匀)的时候有提升 , 但如果是多行单列或者单行多列 (行列数差异较大)的时候 , 并没有提升反而会降低运行效率 ,根据这个特性 , dataframe.eval会只会拖慢效率 。 另一方面, 如果数据量较少 , 使用eval也会降低效率
测试过程中发现eval会增加内存消耗 . 8G内存 ,使用eval时10000*10000 的数据居然跑不下来 , 而直接用加法可以运行出结果
测试结果如下 :
nrows=10000
nclos=5000
df1,df2,df3,df4 = [pd.DataFrame(np.random.randn(nrows,nclos)) for i in range(4)]
%timeit df1+df2+df3+df4
361 ms ± 8.81 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
%timeit pd.eval('df1+df2+df3+df4')
166 ms ± 1.11 ms per loop (mean ± std. dev. of 7 runs, 10 loops each)
nrows=10000*5000
nclos=1
df1,df2,df3,df4 = [pd.DataFrame(np.random.randn(nrows,nclos)) for i in range(4)]
%timeit df1+df2+df3+df4
404 ms ± 8.13 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
%time pd.eval('df1+df2+df3+df4')
1.59 s ± 18.9 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)