急急急!python爬虫数据清洗出错,求各位大佬帮忙!
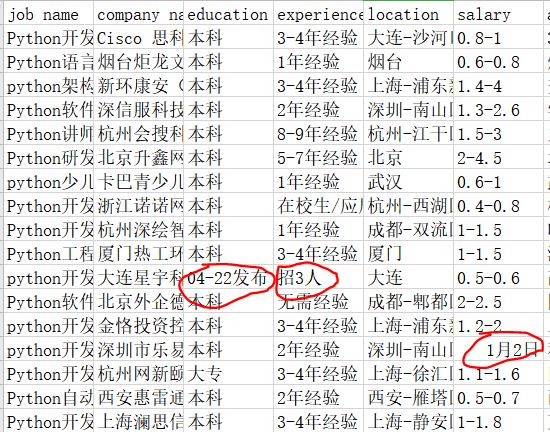
在进行数据清洗的过程中,想要把experience(经验)列的含有"招xx人"的所有行;education(学历)里的含有"XXX发布"清除。
见下图:
具体代码:
def data_clear(df):
#df.drop(columns='job_describe',inplace=True)
#data.drop_duplicates(subset='company_name', inplace=True)
df.dropna(axis=0, how='any', inplace=True) # 删除有缺失值的数据
print('清洗有缺失值的数据后的数据shape:', df.shape)
df = df[df['job name'].str.contains(r'.*?python.*?')] # 挑选含有'...python...'的行
print('挑选职位信息中含有"python"后的数据shape:', df.shape)
#df = df.iloc[:, 1:]
cols1 = [x for i , x in enumerate(df.index) if u'招' in df.loc[i,['experience']]]
df.drop(cols1, axis=0, inplace=True)
print('清洗经验含有招收人数后的数据shape:', df.shape)
#df = df.iloc[:, 1:]
cols3 = [x for i, x in enumerate(df.index) if u'省' in df.loc[i, 'job_place']]
df.drop(cols3, axis=0, inplace=True)
print('清洗区域含有省份后的数据shape:', df.shape)
显示错误:


里面的clos1和clos3这两行具体不知道怎么改
不知道你这个问题是否已经解决, 如果还没有解决的话:- 这篇文章讲的很详细,请看:Python大数据基础之数据清洗(数据转换篇)
如果你已经解决了该问题, 非常希望你能够分享一下解决方案, 以帮助更多的人 ^-^