excludes = {"之","也","吾","与","而","将","了"," ","有","在","为","不","来",
"我","去","皆","又","于","人","乃","见","矣","遂","是","将军","等",
"今","操","中","欲","却说","至","到","此","使","兵","得","从","杀","被",
"便","汝","已","可","出","上","问","走","言","丞相","亦","以","蜀",
"若","令","二人","不可","下","荆州","却","后","寨","只","时","张",
"其","不能","死","如此","斩","无","军","请","说","商议","且",
"如何","回","并","一","主公","他","听","军士","事","左右","就",
"军马","即","引兵","瑜","者","次日","大喜","引","前","二","正",
"看","耳","则","诸","往","耶","你","天下","于是","所","更","东吴",
"郃","起","今日","众","不敢","魏兵","望","退","大","懿","臣","自",
"日","陛下","尽","毕","人马","不知"}
def getText():
txt = open("三国演义.txt", "r", encoding='utf-8').read()
for ch in ',:?!。、;"曰"“”':
txt = txt.replace(ch, " ")
txt = txt.replace("玄德","刘备")
txt = txt.replace("云长","关羽")
txt = txt.replace("关公","关羽")
return txt
open("三国演义.txt", "r", encoding='utf-8').close()
import jieba
sanguoTxt = getText()
words = jieba.lcut(sanguoTxt)
counts = {}
for word in words:
counts[word] = counts.get(word,0) + 1
for word in excludes:
del(counts[word])
items = list(counts.items())
items.sort(key=lambda x:x[1], reverse=True)
for i in range(10):
word, count = items[i]
print ("{0:5}".format(word, count))
```这个是我不需要统计的片段,怎么消除这个519呀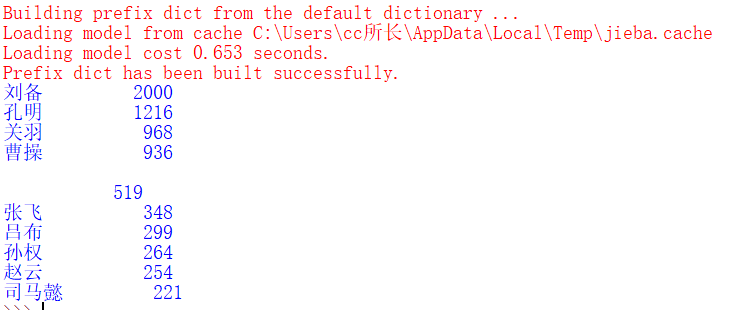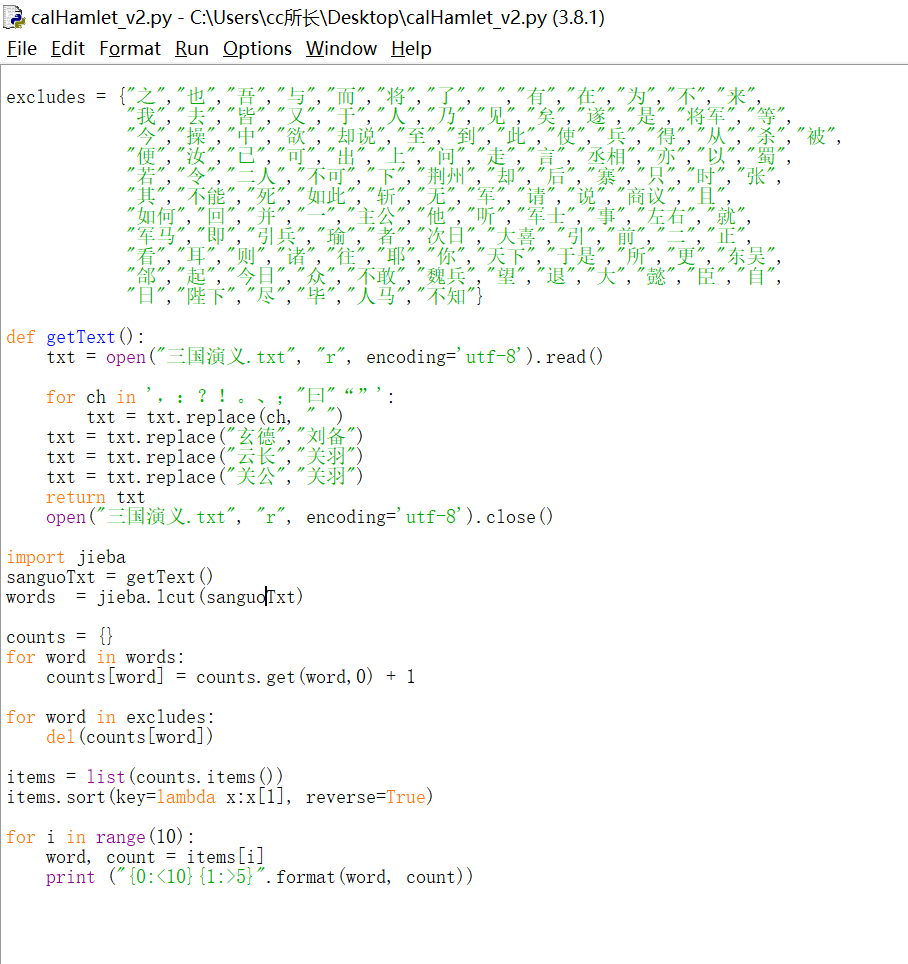
return 后面不应该写东西啊,没有代码不好调试,不过你可以参考这个
https://blog.csdn.net/qq_37465638/article/details/86737435