Python机器学习去掉csv文件中,所有列不满10的行,如果超过10行,则把多余的列去掉,因此不能用pandas
Python机器学习去掉csv文件中,所有列不满10的行,如果超过10行,则把多余的列去掉,因此不能用pandas
提供实现思路如下:
不用 pandas 的话,就只能用文件迭代的方式,读取文件内容,迭代忽略前十行,如果不到10行文件结束,说明文件内容不满足条件。
超过十行的数据再二次处理,用逗号分割取前十列。
是去掉每列长度超过10的行吗?重新写一份csv文件就行,不满10行就不写,超过了10行你再把这行只写前10个进去不就行了?
如果每行的列是,号隔开的话,就先split(',')下呗
import os
with open (r"C:\Users\Administrator\jupyter\data_recent.csv",'r',encoding='utf-8') as f:
with open('.\simple_data.csv','a') as file:
for line in f:
if len(line)>=10:#这里要不要括号不记得了
file.write(line[:10]+'\n')
f.close()
file.close()
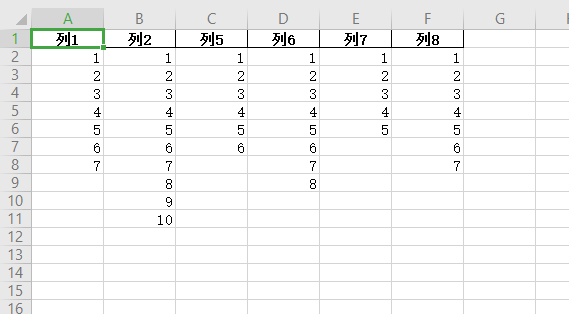
就不知道为啥不能用pandas, 我这用的是excel表做测试的
import pandas as pd
import numpy as np
data = pd.read_excel("./新建 XLSX 工作表.xlsx")
data.drop(list(set(data.columns[np.where(data[11:].notnull())[1]])), axis=1, inplace=True)
data.to_excel("./新建 XLSX 工作表1.xlsx",index=False)
新建 XLSX 工作表.xlsx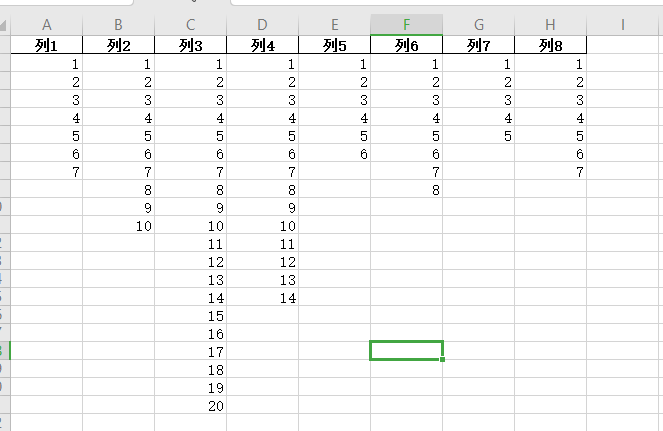
新建 XLSX 工作表1.xlsx