用spyder运行了一段爬虫程序,然后spyder停不下来了。。。。。。
刚刚接触爬虫,看了莫烦的课程,copy了一段简单的代码运行试试,代码如下:
base_url = "https://baike.baidu.com"
his = str.encode("/item/网络爬虫/5162711")
his = str(his)
his = his.replace('\\', '')
his = his.replace('x', '%')
his = his.replace("'", "")
his = his[1:]
his = [his]
url = base_url + his[-1]
html = urlopen(url).read().decode('utf-8')
soup = BeautifulSoup(html, features='lxml')
print(soup.find('h1').get_text(), ' url: ', his[-1])
# find valid urls
sub_urls = soup.find_all("a", {"target": "_blank", "href": re.compile("/item/(%.{2})+$")})
if len(sub_urls) != 0:
his.append(random.sample(sub_urls, 1)[0]['href'])
else:
# no valid sub link found
his.pop()
print(his)
# find valid urls
sub_urls = soup.find_all("a", {"target": "_blank", "href": re.compile("/item/(%.{2})+$")})
if len(sub_urls) != 0:
his.append(random.sample(sub_urls, 1)[0]['href'])
else:
# no valid sub link found
his.pop()
print(his)
for i in range(20):
url = base_url + his[-1]
html = urlopen(url).read().decode('utf-8')
soup = BeautifulSoup(html, features='lxml')
print(i, soup.find('h1').get_text(), ' url: ', his[-1])
# find valid urls
sub_urls = soup.find_all("a", {"target": "_blank", "href": re.compile("/item/(%.{2})+$")})
if len(sub_urls) != 0:
his.append(random.sample(sub_urls, 1)[0]['href'])
else:
# no valid sub link found
his.pop()
代码作用是从百度百科“网络爬虫”这个词条开始,随机且循环爬20个原文中带超链接的词条,好吧这不是重点。
重点是:我在运行完这段程序之后,关闭了原Console,新产生的Console会马上再执行一次这段爬虫程序,如图:In[1]还是空的,上面就执行过程序了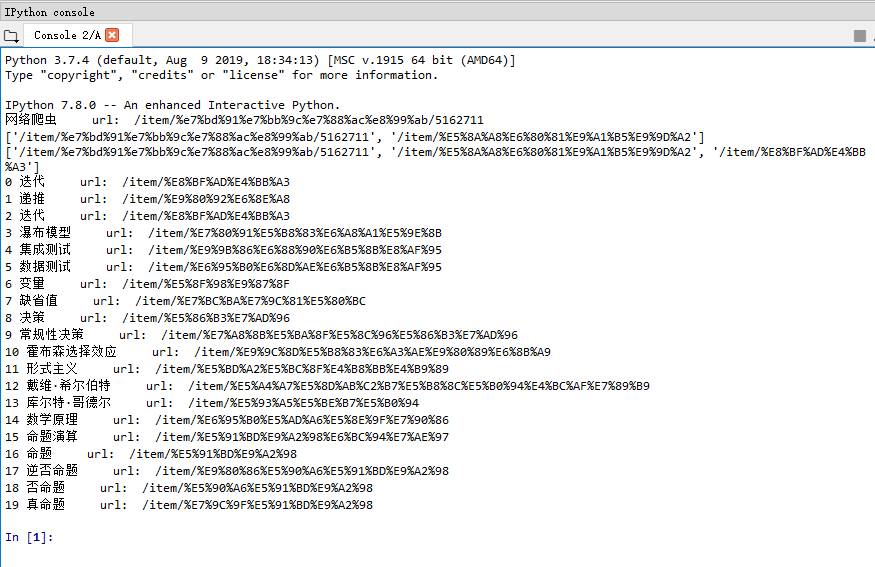
不只如此,如果我不重启spyder的话,运行完其它程序之后也会自动再运行一遍上面这段爬虫代码。
想请教一下大神们这是什么问题,是代码的问题吗,还是编译器bug???
- 关于该问题,我找了一篇非常好的博客,你可以看看是否有帮助,链接:spyder编辑过程中的卡顿问题
如果你已经解决了该问题, 非常希望你能够分享一下解决方案, 以帮助更多的人 ^-^