Python怎么利用sklearn将pandas读取的数据拆分成训练集和验证集
Python用多元线性回归算法对Boston House Price Dataset数据集进行预测中,怎么利用sklearn将pandas读取的数据拆分成训练集和验证集
提供下数据切分思路:
第一,pandas 导入数据,有 load API 方法可以直接用;
第二,对 DataFrame 进行数据切割,就是按照索引规则取不同部分的数据。
参考资料:https://www.jb51.net/article/133653.htm
-*- coding: utf-8 -*-
"""
@File : yolo_dataset_split.py
@Time : 2020/3/7 17:19
@Author : Dontla
@Email : sxana@qq.com
@Software: PyCharm
"""
import os
import re
import cv2
import random
if name == '__main__':
# 定义路径
source_dataset_path = './source_img_dataset/'
train_path = './train.txt'
test_path = 'test.txt'
# 读取source_dataset_path路径下所有文件(包括子文件夹下文件)
filenames = os.listdir(source_dataset_path)
# print(filenames)
# ['1.jpg', '1.txt', '10.jpg',...]
# 提取.jpg
filenames_jpg = []
for i in filenames:
if i.endswith('.jpg'):
filenames_jpg.append(i)
# print(filenames_jpg)
# ['1.jpg', '10.jpg', '100.jpg',...]
# 排序
filenames_jpg.sort(key=len)
# print(filenames_jpg)
# ['1.jpg', '2.jpg', '3.jpg',...]
# 拆分写入
train_scale = 0.75 # 训练集占比
train_file = open(train_path, 'w', encoding='utf-8')
test_file = open(test_path, 'w', encoding='utf-8')
for i in filenames_jpg:
proba = random.random() # 设置随机概率
write_content = ''.join(['data/obj/', i, '\n']) # 创建写入内容
if proba < train_scale: # 判断该写入哪个文件
train_file.write(write_content)
else:
test_file.write(write_content)
train_file.close()
test_file.close()
from sklearn.model_selection import train_test_split
import numpy as np
import pandas as pd
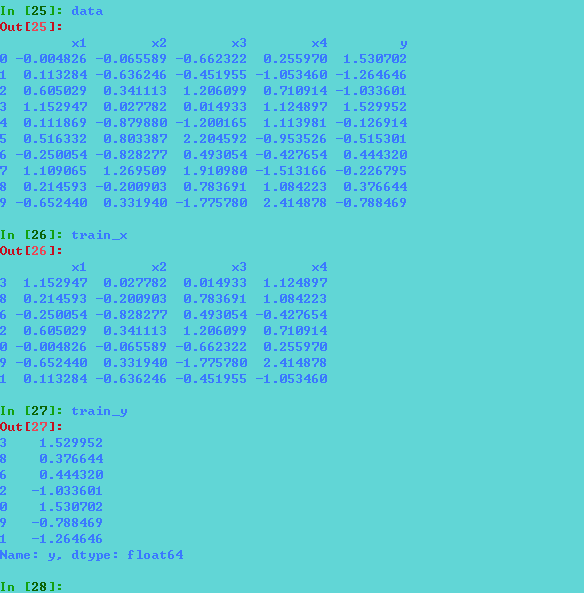
data=pd.DataFrame(np.random.randn(10,5),columns=['x1','x2','x3','x4','y']) #数据样例,需要使用pandas读入你的数据集即可
train_x,test_x,train_y,test_y=train_test_split(data[['x1','x2','x3','x4']],data.y,test_size=0.3)
分割前后数据: