python爬虫运行出现 raise InvalidSchema("No connection adapters were found for '%s'" % url)
import requests
import json
import pandas as pd
import re
from bs4 import BeautifulSoup
headers = {}
headers['user-agent'] = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36' #http头大小写不敏感
headers['accept'] = '*/*'
headers['Connection'] = 'keep-alive'
headers['Pragma'] = 'no-cache'
def getUrls():
urls = []
for year in range(2019,2020):
for month in range(1,13):
if month<10:
urls.append("http://tianqi.2345.com/t/wea_history/js/%s0%s/58321_%s0%s.js" %(year,month,year,month))
else:
urls.append("http://tianqi.2345.com/t/wea_history/js/%s%s/58321_%s%s.js" %(year,month,year,month))
return urls
url = getUrls()
res = requests.get(url)
a=res.text
data=json.dumps(a, indent=2,ensure_ascii=False)
b=a.split('[')
c=b[1].replace('"','')
f=re.findall(r'\{(.*?)\}', str(c))
tianqi=[]
for i in f[:-1]:
i={i.replace("'",'')}
xx= re.sub("[A-Za-z\!\%\[\]\,\。]", " ", str(i))
yy=xx.split(' ')
tianqi.append([data[24:26], yy[3][1:], yy[10][1:-1], yy[17][1:-1], yy[24][1:], yy[34][1:],yy[41][1:], yy[45][1:],yy[53][1:]])
print('日期 最高气温 最低气温 天气 风向风力 空气质量指数')
print(tianqi)
weather=pd.DataFrame(tianqi)
weather.columns=['城市',"日期","最高气温","最低气温","天气","风向",'风力','空气质量指数','空气质量']
weather.to_csv(str(data[24:26])+'.csv',encoding="utf_8_sig")
运行后出现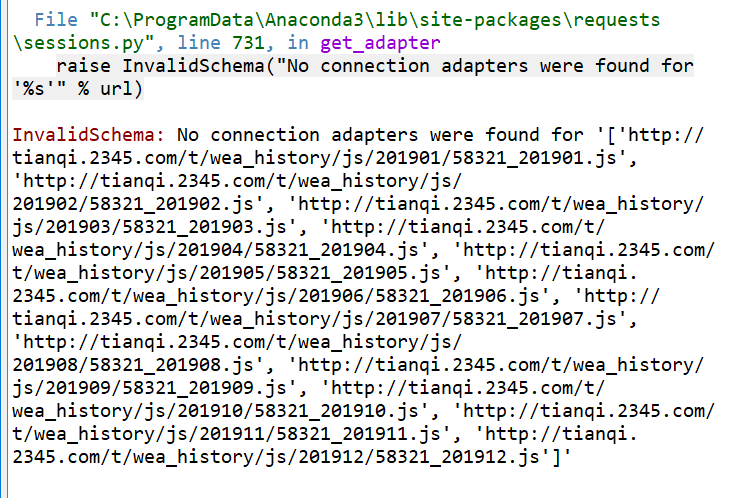
请问各位大佬这是出了什么问题
requests.get(url)
试试看单个url,而不是url列表
还有检查网络是不是通
url后面的多了双引号,url = url.strip(string.punctuation) 去除最后的双引号,试试