基于scrapy框架爬虫,XPath正确,但是有一项爬不出东西,跪求各位大佬如何解决?
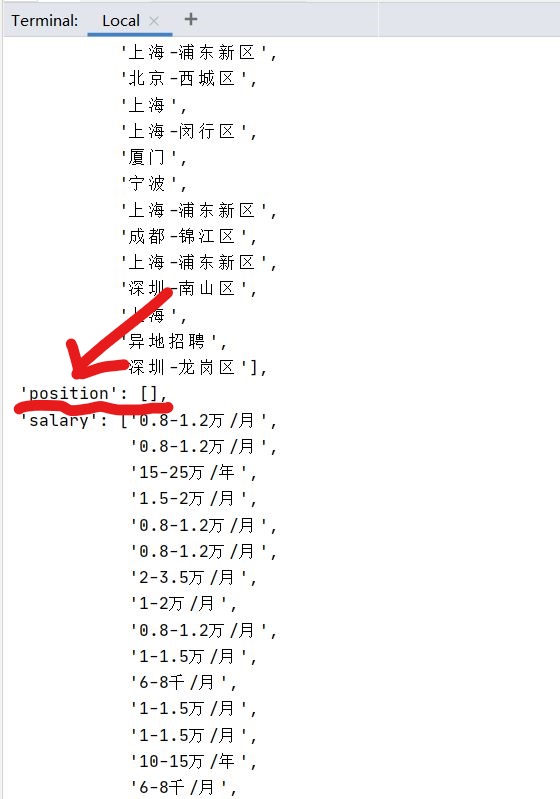

代码如下:
import requests
import scrapy
import bs4
from crawler51job.items import Crawler51JobItem
from scrapy.http import Request
class Spider51jobSpider(scrapy.Spider):
name = 'spider51job'
allowed_domains = ['www.51job.com']
start_urls = ['https://search.51job.com/list/000000,000000,0000,00,9,99,python,2,1.html']
def parse(self, response):
item = Crawler51JobItem()
item['position'] = response.xpath('//p[@class="t1"]/span/a/@title').extract()
item['company'] = response.xpath('//span[@class="t2"]/a/@title').extract()
item['place'] = response.xpath('//div[@class="el"]/span[@class="t3"]/text()').extract()
item['salary'] = response.xpath('//div[@class="el"]/span[@class="t4"]/text()').extract()
yield item
for i in range(2,5):
url='https://search.51job.com/list/000000,000000,0000,00,9,99,python,2,"+str(i)+".html'
yield Request(url,callback=self.parse)
- 你可以参考下这篇文章:(Scrapy框架)爬虫获取豆瓣正在热映的电影信息,xpath属性爬取 | 爬虫案例
如果你已经解决了该问题, 非常希望你能够分享一下解决方案, 以帮助更多的人 ^-^