文件夹下txt批量提取列并处理
新手求教,处理数据时使用(急),在网上搜索并尝试无果,请问如何通过python或bat实现以下目标:
1.对文件夹下的所有txt文件批量提取某几列数据(不相邻),并分别放入与原文件名对应的txt内(文本名为“原文本名+tm”);
2.对提取后的txt中某列数据进行运算:原数据×0.1;及特征数字数据替换;
以一个txt为例描述:
如图示,提取第6、7、8、10列数据至新的txt文本,文本名为50136tn;对第10列数据进行“×0.1”运算,并将32766数值替换为99999。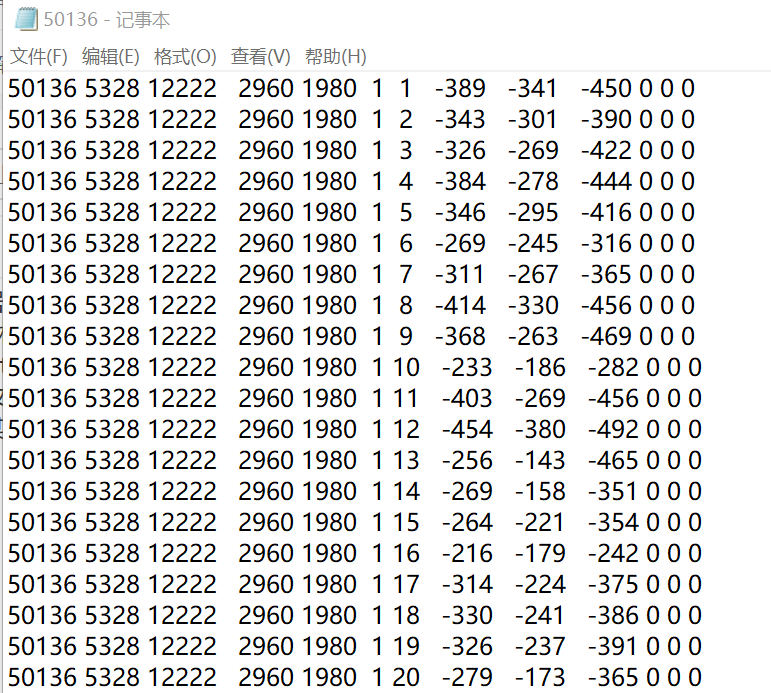
不胜感激!
首先将数据每行的分隔符都换成单空格
程序自带将多空格变为单空格
import os
import glob
os.chdir('存储数据的目录(绝对路径)')
txt = glob.glob('*.txt')
for i in txt:
f = open(i)
res = ''
data = f.read()
data = data.replace(' ',' ')
for j in data.split('\n'):
k = j.split(' ')
k[9] = str(double(k[9])/10)# 第十列,所以要将索引减一为九的项目处理
for l in range(len(k)):
if k[l] == '32766':
k[l] = '99999'
res += ' '.join(k) + '\n'
resf = open(i[:-4]+'tm.txt', mode='wt')
resf.write(res)
f.close()
resf.close()
望采纳
https://blog.csdn.net/weixin_44560020/article/details/101010820
我也是新手,我觉得可以先用一个字典,键为行数,值中把行中的数据用列表放进去,输出的时候直接输出每一行的指定列就行,如num[n][6],n给他一个自增,运算的话我觉得可以在写入文件的时候就计算,用新值替换字典中的旧值,特征替换用一个简单的匹配搜索就行
借助python的pandas和os模块可以很快的实现你的需求。
pandas:来提取的处理数据,pandas是第三方模块,需要安装
os:文件的遍历和文件的穿件和删除,os是内置模块可以直接使用而无需安装