请求各位大神指出下面一段python爬虫代码的问题:
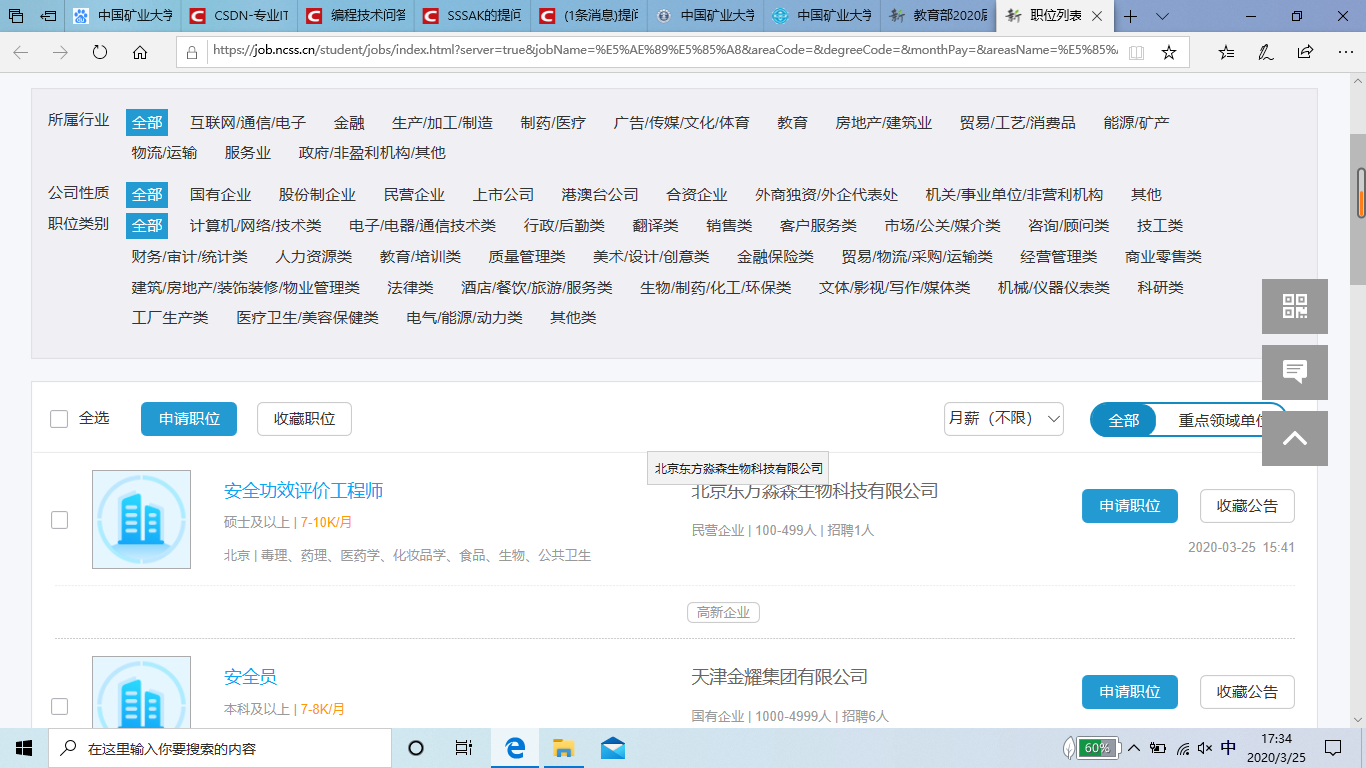
我想在24365官网上爬取招聘信息中的岗位名称和公司名称到EXCEL表格中,但运行代码后表格里只有标题,没有内容,要爬取的网站如图所示:
import urllib.request,traceback
import re
import xlwt #用来创建excel文档并写入数据
def get_content(page):
url = 'https://job.ncss.cn/student/jobs/index.html?server=true&jobName=%E5%AE%89%E5%85%A8&areaCode=°reeCode=&monthPay=&areasName=%E5%85%A8%E5%9B%BD'+str(page)+'.html'
a = urllib.request.urlopen(url)#打开网址
html = a.read().decode('utf-8')#读取源代码并转为unicode
return html
def get(html):
reg = re.compile(r'class="company-name" .*?>(.*?)</span>.*?<span>(.*?)</span>',re.S)#匹配换行符,设置正则表达式
items = re.findall(reg,html)
return items
def excel_write(items,index):
#爬取到的内容写入excel表格
for item in items:#职位信息
for i in range(0,2):
#print item[i]
ws.write(index,i,item[i])#行,列,数据
print(index)
index+=1
newTable="test2.xls"#表格名称
wb = xlwt.Workbook(encoding='utf-8')#创建excel文件,声明编码
ws = wb.add_sheet('sheet1')#创建表格
headData = ['公司','类型']#表头部信息
for colnum in range(0,2):
ws.write(0, colnum, headData[colnum], xlwt.easyxf('font: bold on')) # 行,列
for each in range(1,10):
index=(each-1)*50+1
excel_write(get(get_content(each)),index)
wb.save(newTable)
该网站爬取内容所需的审查元素在下图的蓝色位置: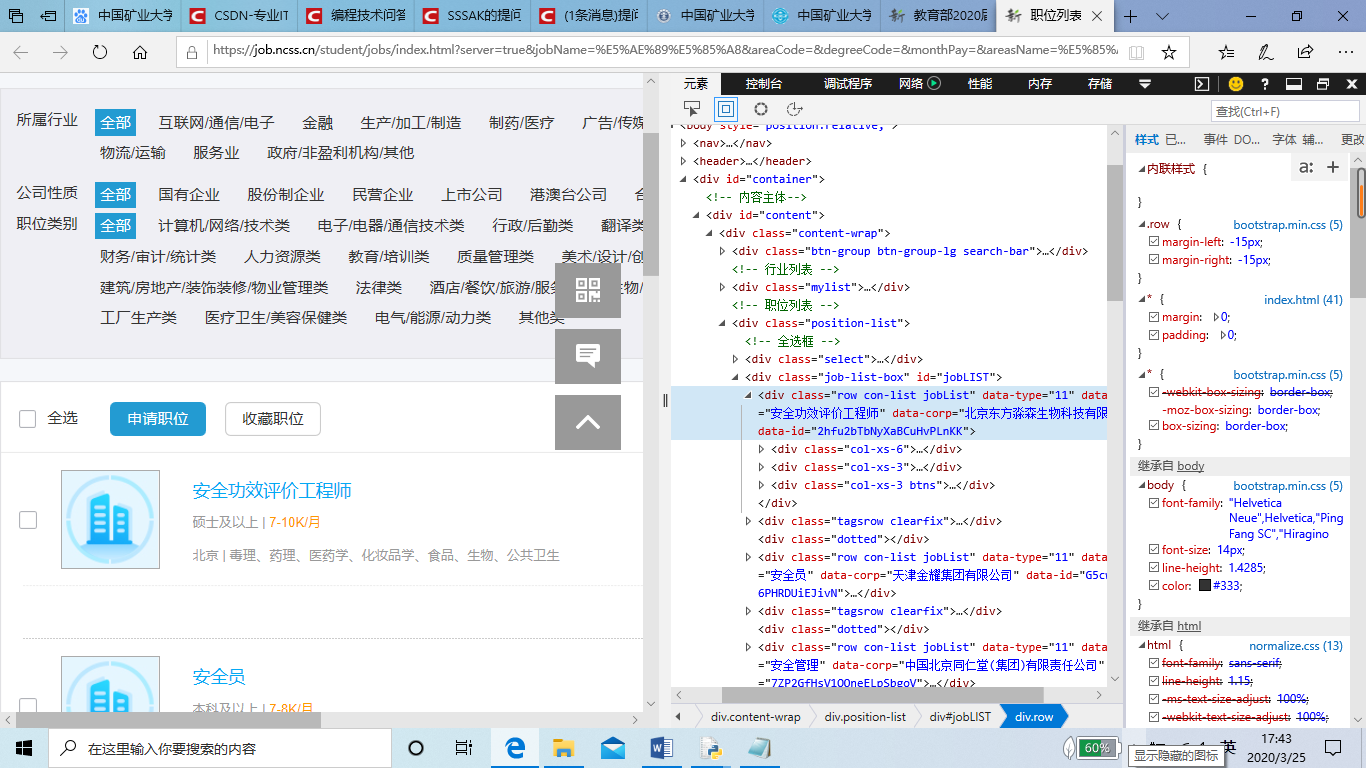
审查元素具体内容如下:
这个网页是动态加载的,你要获取内容,需要找到它获取内容的请求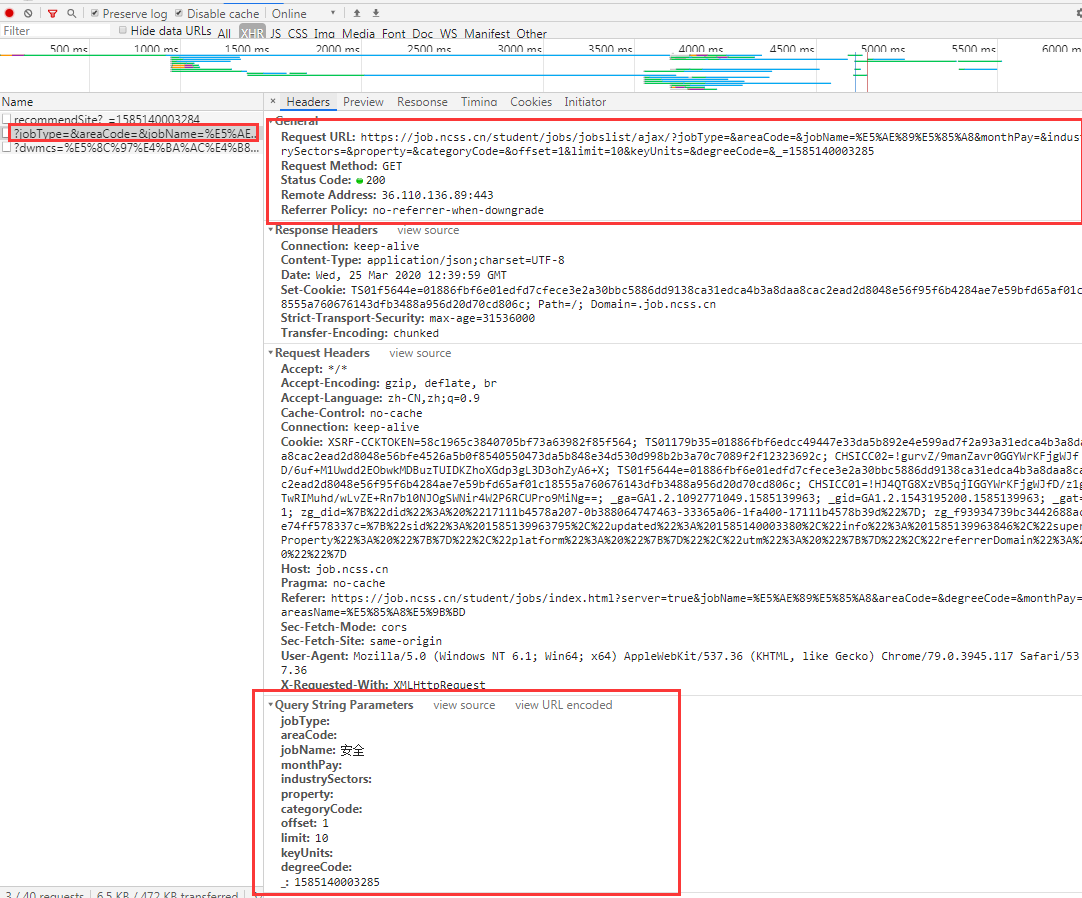
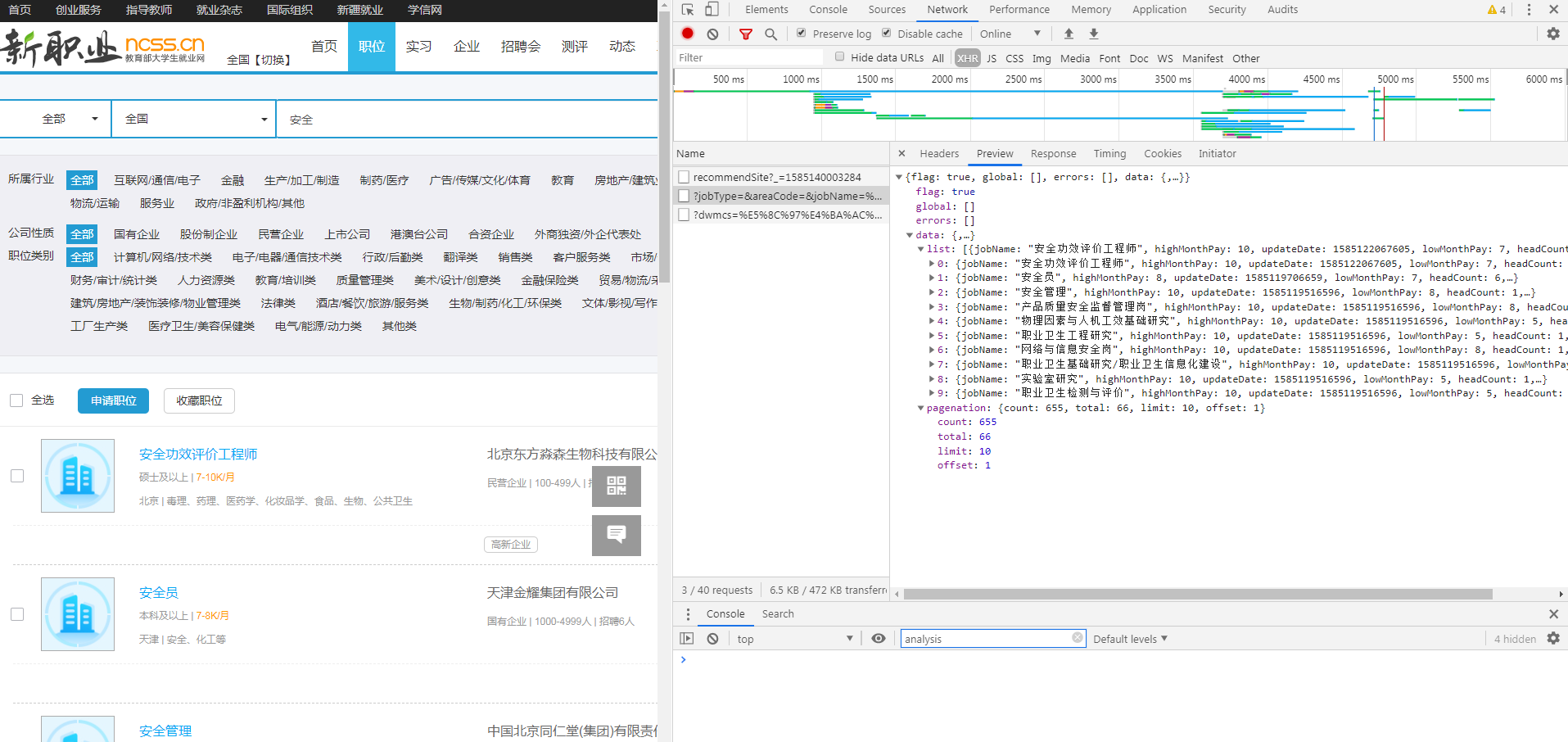
使用requests库写了一个简单的代码,你也可以用requests库来写爬虫,比urllib简单太多了,我当初也是踩了urllib的坑,用pip安装一下就可以了
import requests
url="https://job.ncss.cn/student/jobs/jobslist/ajax/"
params={
"jobName": "安全", #搜索关键字
"offset": "1", #偏移,应该就是页码
"limit": "10", #每页的个数
}
req=requests.get(url,params).json(); #这里得到一个解析json之后得到一个字典对象
for it in req['data']['list']: #可以先监视查看一下结构,输出即可
print(it);
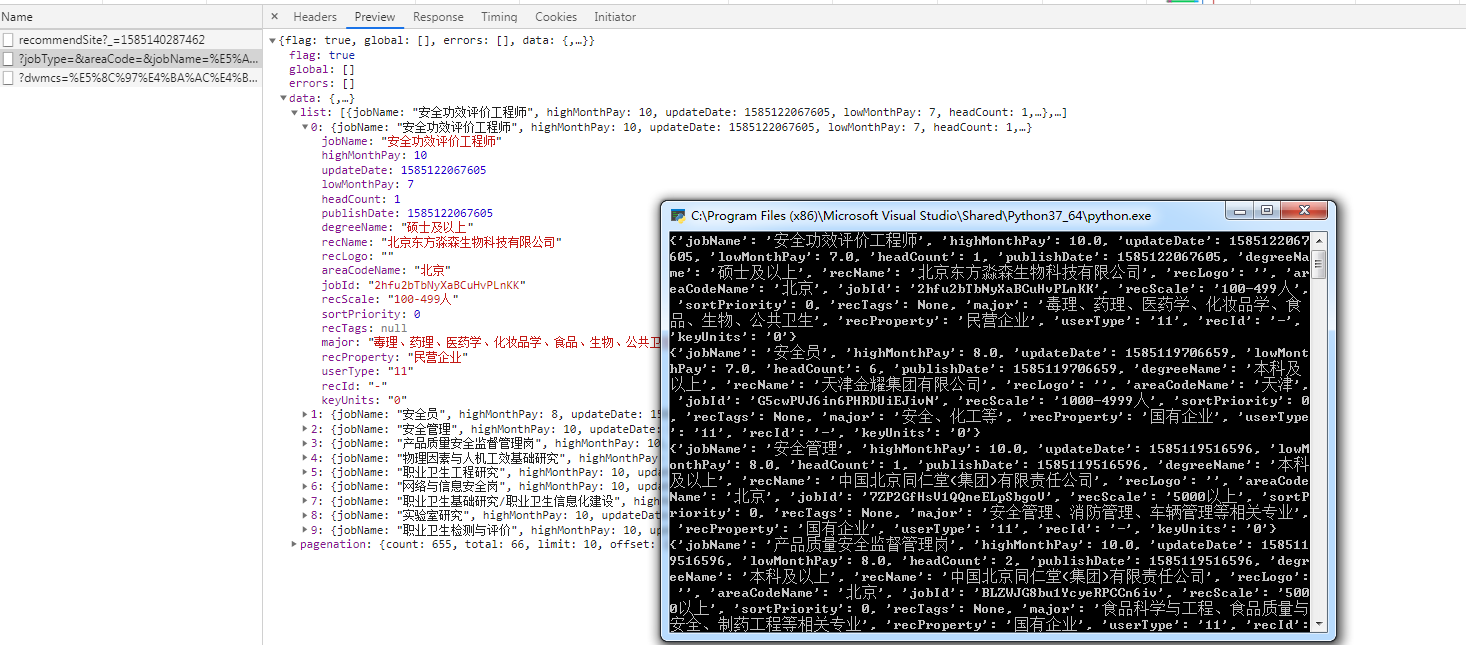
这个用了js动态生成,一种反爬虫机制,建议去学学怎么爬