scrapy引擎为什么没有开启spider
spider代码如下
import scrapy,re
from ..items import LianjiaItem
class LjSpider(scrapy.Spider):
name = 'lj'
allowed_domains = ['lianjia.com/city/']
start_urls = ['https://www.lianjia.com/city/']
def parse(self, response):
city_list = response.css('.city_list_ul li .city_list ')
for city in city_list:
city_name = city.css('li a ::text').get()
if city_name == '西安':
city_url = city.css('li a ::attr(href)').get()
item = LianjiaItem(city=city_name)
print(city_name,city_url)
yield scrapy.Request(city_url + 'zufang/rs/',callback=self.parse_regin,meta={'item':item})
def parse_regin(self, response):
regin_list = response.css('.filter__item--level2 ')
for regin in regin_list:
regin_name = regin.css('a ::attr(href)').get()
if regin_name == '雁塔':
regin_url = regin.css('a ::text').get()
item = LianjiaItem(regin=regin_name)
yield scrapy.Request(response.urljion(regin_url),callback=self.page_url, meta={'item':item})#此处网站有变化,item
def page_url(self, response):
page_list = response.css('ul[style="display:hidden"] a ::attr(href)').getall()
for page_url in page_list:
if page_url:
yield scrapy.Request(response.urljion(page_url),callback=self.parse_house, meta={'item':response.meta.get('item')})
def parse_house(self, response):
url_list = response.css('.content__list--item--main p a ::attr(href)').getall()
for url in url_list:
url = re.search(r'/zufang/\.+\.html',url)
house_url = "xa.lianjia.com" + url #此处网站有变化
yield scrapy.Request(house_url,callback=self.parse_detail,meta={'item':response.meta.get('item')})
def parse_detail(self, response):
title = response.css('.content__title ::text').get()
prices = response.css('.content__aside--title::text').getall()
price = ''.join(prices).strip()
area = response.css('.content__aside__list li:nth-child(2) ::text').getall()[2]
fl = response.css('.content__article__info2 li[class$="line"] ::text').getall()
fl = ''.join(fl).strip()
item = LianjiaItem(title=title,price=price,area=area,fl=fl
)
yield item
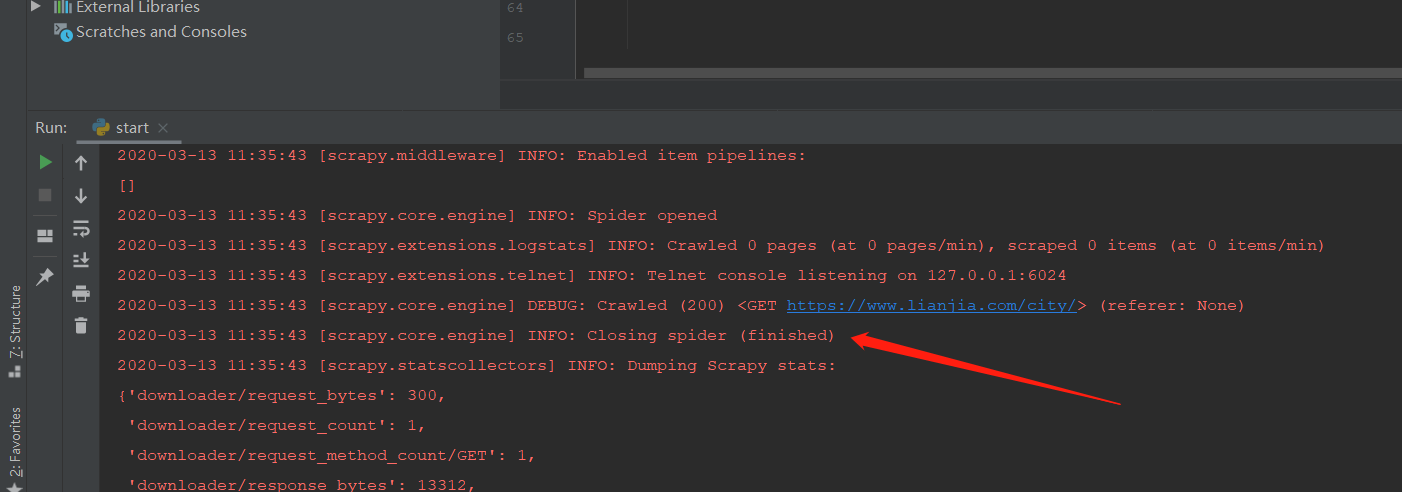
- 建议你看下这篇博客👉 :Scrapy中如何向Spider传入参数
如果你已经解决了该问题, 非常希望你能够分享一下解决方案, 以帮助更多的人 ^-^