通过requests.get()方法获取到的html中对应的div中无数据
疫情原因在家没事,想通过网站:
https://wp.m.163.com/163/page/news/virus_report/index.html?_nw_=1&_anw_=1
获取每日的疫情情况(此处为确诊人数)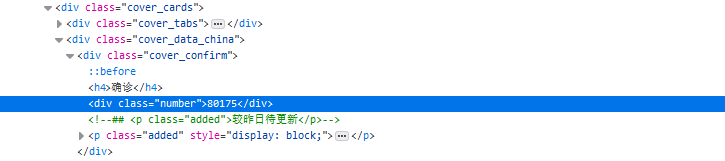
结果获取的html中并没有数据,仅有横杠,如下
代码:
r=requests.get('https://wp.m.163.com/163/page/news/virus_report/index.html',params={'_nw_':1,'_anw_':'1'})
r=r.content
print(r)
txt=etree.HTML(r)
print(txt)
各位大佬帮忙看看
谢谢大佬天际的海浪点拨
在查看了相关爬虫的文章
通过request.get()方法获取到的网页是静态的,但是数据是通过json传入的。
需要通过F12工具查看js及xhr,确定数据来源
这个是用ajax获取数据,动态更新页面的
你要的数据在这里
https://c.m.163.com/ug/api/wuhan/app/data/list-total
"total":{"confirm":80175,"suspect":715,"heal":44802,"dead":2915},