python 爬虫 输出数字却显示为乱码
查看网页代码发现数字被转码了,导致python输出结果全是乱的。代码如下:
# coding:utf-8
from selenium import webdriver
browser = webdriver.Chrome()
# chrome_options = webdriver.ChromeOptions()
# chrome_options.add_argument('--headless')
# browser = webdriver.Chrome(chrome_options=chrome_options)
# browser = webdriver.PhantomJS()
# browser.maximize_window() # 最大化窗口,可以选择设置
browser.get('http://data.eastmoney.com/kzz/default.html')
element = browser.find_element_by_css_selector('#dt_1')
# 提取表格内容td
td_content = element.find_elements_by_tag_name("td")
lst = []
for td in td_content:
lst.append(td.text)
print(lst)
网页乱码定位图片如下已上传!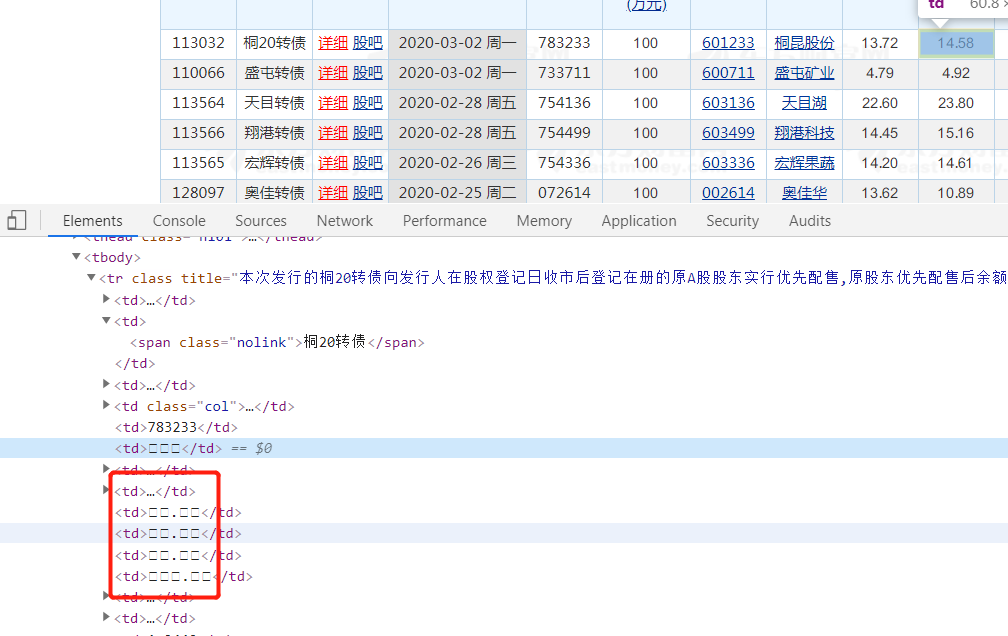
https://www.jb51.net/article/102070.htm
老哥找到解决办法了嘛,我也遇到了相同的问题,数据是数字和字母,但是用selenium获取到的就是和你一样的格式
估计是为了防止你们抓取数据,所以用了特殊字符+特殊字体,使得看上去是数据,抓到的是特殊字符。你得找到字符编码和数字的关系,再替换回来。
把编码转换一下