【新手问题】如何将dataframe结构中的人名字符串拆分后统计出现次数
题主刚学pandas不久,遇到这个问题希望各位大大帮忙解决。
希望在一份电影数据表中统计重复出现次数前几位的演员名称,原始dataframe数据格式如下: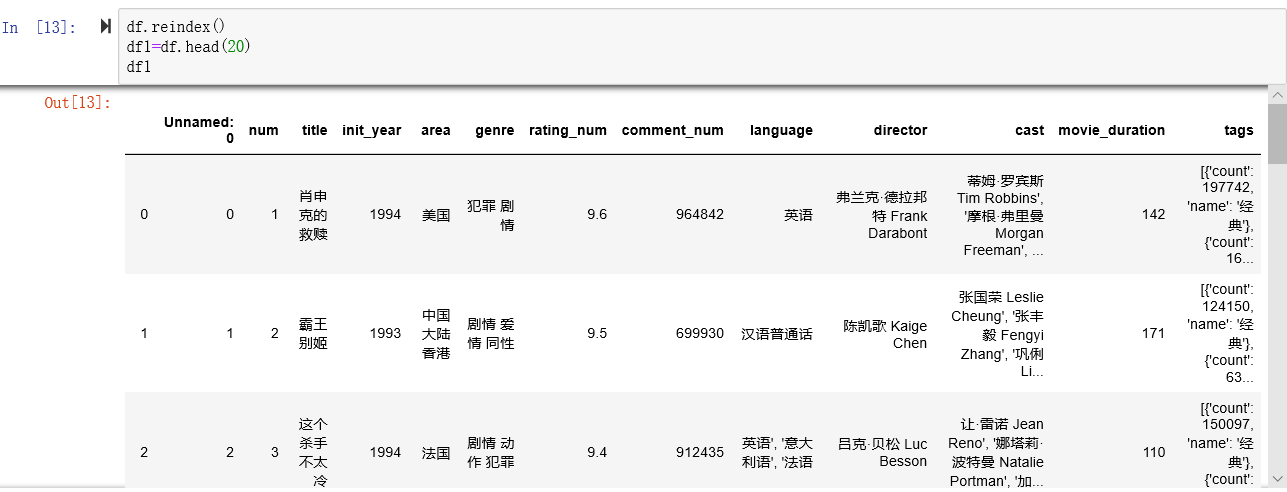
这是想要进行字符串统计的cast序列内容
尝试使用了values_count()方法,没有效果
也尝试了Counter()方法,报错unhashed list
想知道如何正确运用分隔符把这些数据切成单个的字符串并存入列表的形式,再进行统计
还有想知道unhashed list报错的解决方法,网上只说了为什么但是好像查不到如何解决
谢谢各位大大
————————————————————————————————
补充一个新问题,同样与计数有关
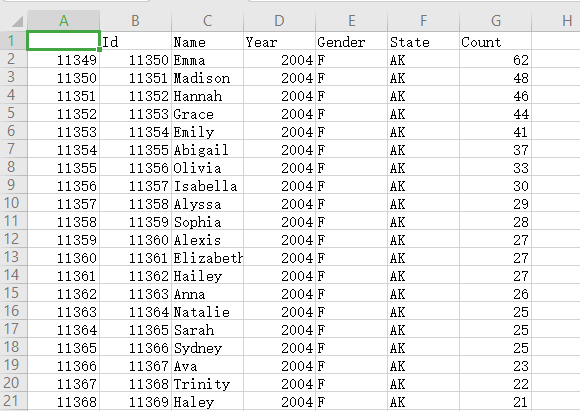
如何计算各个州的婴儿出生性别F和M的总和,想要绘制成并列条形图的形式,但是用duplicated()方法好像统计不出来,需要用自定义函数生成,想了半天没想通,希望大大们顺便支个招。
不知道你这个问题是否已经解决, 如果还没有解决的话:- 给你找了一篇非常好的博客,你可以看看是否有帮助,链接:对Dataframe中异常值检测求助
如果你已经解决了该问题, 非常希望你能够分享一下解决方案, 写成博客, 将相关链接放在评论区, 以帮助更多的人 ^-^