python 爬取表格 获取不到数据
我使用python爬取网页表格数据的时候使用 request.get获取不到页面内容。
爬取网址为:http://data.10jqka.com.cn/rank/cxg/board/4/field/stockcode/order/desc/page/2/ajax/1/free/1/
这是Elements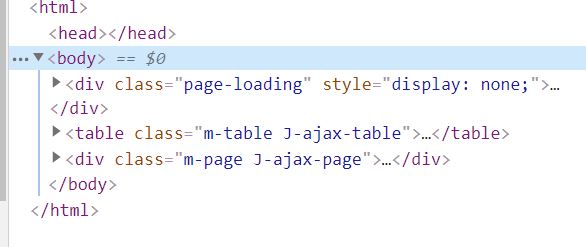
import os
import requests
from lxml import etree
url='http://data.10jqka.com.cn/rank/cxg/board/4/field/stockcode/order/desc/page/2/ajax/1/free/1/'
#url1='http://data.10jqka.com.cn/rank/cxg/'
headers={'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.106 Safari/537.36'}
res = requests.get(url, headers=headers)
res_elements = etree.HTML(res.text)
table = res_elements.xpath('/html/body/table')
print(table)
table = etree.tostring(table[0], encoding='utf-8').decode()
df = pd.read_html(table, encoding='utf-8', header=0)[0]
results = list(df.T.to_dict().values()) # 转换成列表嵌套字典的格式
df.to_csv("std.csv", index=False)
res.text 里的数据为 (不包含列表数据)
'<html><body>\n <script type="text/javascript" src="//s.thsi.cn/js/chameleon/chameleon.min.1582008.js"></script> <script src="//s.thsi.cn/js/chameleon/chameleon.min.1582008.js" type="text/javascript"></script>\n <script language="javascript" type="text/javascript">\n window.location.href="http://data.10jqka.com.cn/rank/cxg/board/4/field/stockcode/order/desc/page/2/ajax/1/free/1/";\n </script>\n </body></html>\n'
爬取需要在请求头里面添加Host,要不然爬取不到任何信息,另外源码是不规则的html代码,所以需要指定html解析器
# -*- coding:utf-8 -*-
import os
import requests
from lxml import etree
import pandas as pd
url='http://data.10jqka.com.cn/rank/cxg/board/4/field/stockcode/order/desc/page/2/ajax/1/free/1/'
headers={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.106 Safari/537.36',
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3",
"Host":"data.10jqka.com.cn",
}
res = requests.get(url, headers=headers)
parser = etree.HTMLParser(encoding='utf-8') #指定html解析器
res_elements = etree.HTML(res.text,parser=parser)
table = res_elements.xpath('/html/body/table')
print(table)
table = etree.tostring(table[0], encoding='utf-8').decode()
df = pd.read_html(table, encoding='utf-8', header=0)[0]
results = list(df.T.to_dict().values()) # 转换成列表嵌套字典的格式
df.to_csv("std.csv", index=False)
首先检查
res = requests.get(url, headers=headers)
这一行能返回 html 么
然后检查 res_elements = etree.HTML(res.text) 解析成功没有
print(table) 然后看这里输出对不对
最后看results = list(df.T.to_dict().values()) 这里
import os
import requests
from lxml import etree
import pandas as pd
import time
FileNamePrefix = time.strftime("%Y-%m-%d %H %M %S", time.localtime())
headers={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.106 Safari/537.36',
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3",
"Host":"data.10jqka.com.cn",
}
def GetSinglePageData(page):
url = 'http://data.10jqka.com.cn/rank/cxg/board/4/field/stockcode/order/desc/page/%s/ajax/1/free/1/' % page
res = requests.get(url, headers=headers)
parser = etree.HTMLParser(encoding='utf-8') #指定html解析器
res_elements = etree.HTML(res.text,parser=parser)
table = res_elements.xpath('/html/body/table')
table = etree.tostring(table[0], encoding='utf-8').decode()
df = pd.read_html(table, encoding='utf-8', header=0)[0]
results = list(df.T.to_dict().values()) # 转换成列表嵌套字典的格式
if len(results) > 0:
print("第%s页获取数据成功!" % page)
else:
print("第%s页获取数据失败!" % page)
df.to_csv(FileNamePrefix + " std.csv", mode='a', encoding='utf_8_sig', header=1,index=0)
#获取总页数
def GetTotalPage():
url = 'http://data.10jqka.com.cn/rank/cxg/board/4/field/stockcode/order/desc/page/1/ajax/1/free/1/'
res = requests.get(url, headers=headers)
parser = etree.HTMLParser(encoding='utf-8')
html = etree.HTML(res.text, parser=parser)
html_data = html.xpath("/html/body/div[2]/a[text()='尾页']")
return html_data[0].attrib['page']
if __name__ == '__main__':
for i in range(1, int(GetTotalPage()) + 1):
GetSinglePageData(i)
我测试没问题,你再试试
你可以看看是否为动态加载页面,如果是,你可以使用selenium库的webdriver来动态爬取
首先在你的浏览器上安装对应的插件(例如我的浏览器是chrome)
driver = webdriver.Chrome
driver.get('website')
如果要想保存登录信息,可以去我的博文里看看