PTA|L2-022 链表重排 求大佬点波拨一下哪里错了
给定一个单链表 L1
→L
2
→⋯→L
n−1
→L
n
,请编写程序将链表重新排列为 L
n
→L
1
→L
n−1
→L
2
→⋯。例如:给定L为1→2→3→4→5→6,则输出应该为6→1→5→2→4→3。
输入格式:
每个输入包含1个测试用例。每个测试用例第1行给出第1个结点的地址和结点总个数,即正整数N (≤10
5
)。结点的地址是5位非负整数,NULL地址用−1表示。
接下来有N行,每行格式为:
Address Data Next
其中Address是结点地址;Data是该结点保存的数据,为不超过10
5
的正整数;Next是下一结点的地址。题目保证给出的链表上至少有两个结点。
输出格式:
对每个测试用例,顺序输出重排后的结果链表,其上每个结点占一行,格式与输入相同。
输入样例:
00100 6
00000 4 99999
00100 1 12309
68237 6 -1
33218 3 00000
99999 5 68237
12309 2 33218
输出样例:
68237 6 00100
00100 1 99999
99999 5 12309
12309 2 00000
00000 4 33218
33218 3 -1
结果如下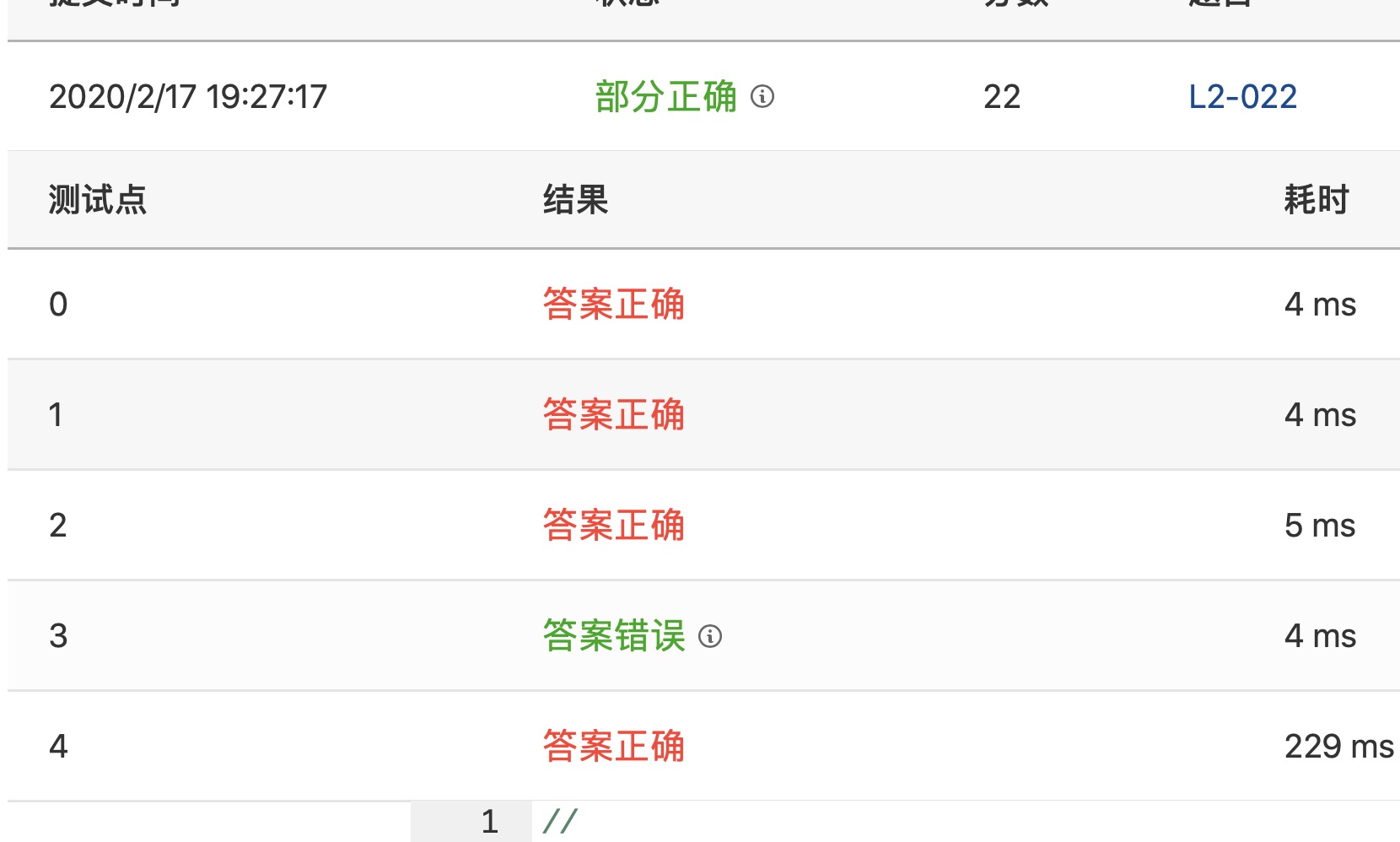
#include <iostream>
#include <cstring>
using namespace std;
const int maxn=1e5;
int _data[maxn];
int _next[maxn];
int main(){
int add,n;
cin>>add>>n;
memset(_next, -1, sizeof(_next));
for(int i=1;i<=n;i++){
int id,data,next;
cin>>id>>data>>next;
_data[id]=data;
_next[id]=next;
}
int flag=1;
int rank[n+1];//第四组测试用例会越界,但改大是答案错误
for(int i=add;i!=-1;i=_next[i]){
rank[flag++]=i;
}
if(n%2!=0&&n>=3){
int temp=(n-1)/2;
for(int i=1;i<=temp;i++){
printf("%05d %d %05d\n",rank[n-i+1],_data[rank[n-i+1]],rank[i]);
printf("%05d %d %05d\n",rank[i],_data[rank[i]],rank[n-i]);
}
temp=(n+1)/2;
printf("%05d %d %d",rank[temp],_data[rank[temp]],-1);
}
else if(n==1){
printf("%05d %d %d",rank[1],_data[rank[1]],-1);
}
else if(n==2){
printf("%05d %d %05d\n",rank[2],_data[rank[2]],rank[1]);
printf("%05d %d %d",rank[1],_data[rank[1]],-1);
}
else {
int temp=n/2;
for(int i=1;i<temp;i++){
printf("%05d %d %05d\n",rank[n-i+1],_data[rank[n-i+1]],rank[i]);
printf("%05d %d %05d\n",rank[i],_data[rank[i]],rank[n-i]);
}
printf("%05d %d %05d\n",rank[temp+1],_data[rank[temp+1]],rank[temp]);
printf("%05d %d %d",rank[temp],_data[rank[temp]],-1);
}
}
输出的时候令n=flag-1,参考这篇博客,应该算是边界判断里比较奇葩的一个坑了吧。
另外楼主的输出逻辑可以简化为一个循环,核心输出代码可优化为如下,数组表示用0...n-1替代,PTA测试全通过
int flag=0;
for(int i=add;i!=-1;i=_next[i]){
rank[flag++]=i;
}
n=flag;
for(int i=0;i<n-1;i++){
int a = i%2 ? (i-1)/2 : n-i/2-1;
int b = i%2 ? n-i/2-2 : i/2;
printf("%05d %d %05d\n",rank[a],_data[rank[a]],rank[b]);
}
int a = (n-1)/2;
printf("%05d %d %d\n",rank[a],_data[rank[a]],-1);
蔡能教授直接抄的那个链接,一个字都没改的,如果楼主懒得看链接可以看蔡能教授的,不过重点不是代码
https://blog.csdn.net/weixin_44161380/article/details/88876447
代码
#include<iostream>
#include<cmath>
#include<cstring>
#include<algorithm>
#include<vector>
#include<set>
using namespace std;
struct lian
{ int zhi,next;
}b[100005];
vector<int> o;
int main()
{ int m,beginn;
cin>>beginn>>m;
for(int i=0;i<m;i++)
{ int a;
cin>>a;
cin>>b[a].zhi>>b[a].next;
}
int p=beginn;
while(1)
{ if(p==-1) break;
o.push_back(p);
p=b[p].next;
}
int qian=0,hou=o.size()-2;
printf("%05d %d",o[o.size()-1],b[o[o.size()-1]].zhi);
while(qian<=hou)
{ printf(" %05d\n%05d %d",o[qian],o[qian],b[o[qian]].zhi);
if(hou==qian) break;
printf(" %05d\n%05d %d",o[hou],o[hou],b[o[hou]].zhi);
qian++;
hou--;
}
cout<<" "<<-1<<endl;
return 0;
}
赞同教授的观点, while(qian<=hou) 这个循环就可以