openCV_python自带的ANN进行手写字体识别,报错。求助

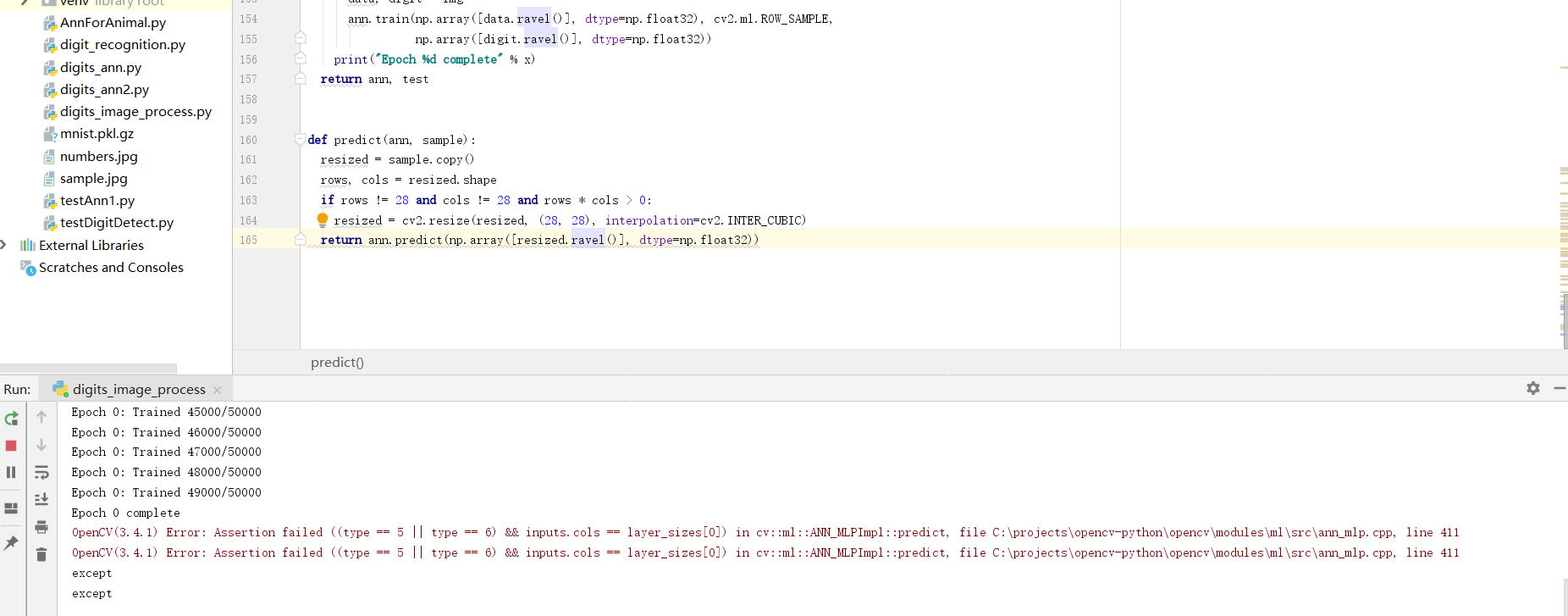
我用python3.6按照《OpenCV3计算机视觉》书上代码进行手写字识别,识别率很低,运行时还报了错:OpenCV(3.4.1) Error: Assertion failed ((type == 5 || type == 6) && inputs.cols == layer_sizes[0]) in cv::ml::ANN_MLPImpl::predict, file C:\projects\opencv-python\opencv\modules\ml\src\ann_mlp.cpp, line 411
具体代码如下:求大佬指点下
import cv2
import numpy as np
import digits_ann as ANN
def inside(r1, r2):
x1, y1, w1, h1 = r1
x2, y2, w2, h2 = r2
if (x1 > x2) and (y1 > y2) and (x1 + w1 < x2 + w2) and (y1 + h1 < y2 + h2):
return True
else:
return False
def wrap_digit(rect):
x, y, w, h = rect
padding = 5
hcenter = x + w / 2
vcenter = y + h / 2
if (h > w):
w = h
x = hcenter - (w / 2)
else:
h = w
y = vcenter - (h / 2)
return (int(x - padding), int(y - padding), int(w + padding), int(h + padding))
'''
注意:首次测试时,建议将使用完整的训练数据集,且进行多次迭代,直到收敛
如:ann, test_data = ANN.train(ANN.create_ANN(100), 50000, 30)
'''
ann, test_data = ANN.train(ANN.create_ANN(10), 50000, 1)
# 调用所需识别的图片,并处理
path = "C:\\Users\\64601\\PycharmProjects\Ann\\images\\numbers.jpg"
img = cv2.imread(path, cv2.IMREAD_UNCHANGED)
bw = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
bw = cv2.GaussianBlur(bw, (7, 7), 0)
ret, thbw = cv2.threshold(bw, 127, 255, cv2.THRESH_BINARY_INV)
thbw = cv2.erode(thbw, np.ones((2, 2), np.uint8), iterations=2)
image, cntrs, hier = cv2.findContours(thbw.copy(), cv2.RETR_TREE, cv2.CHAIN_APPROX_SIMPLE)
rectangles = []
for c in cntrs:
r = x, y, w, h = cv2.boundingRect(c)
a = cv2.contourArea(c)
b = (img.shape[0] - 3) * (img.shape[1] - 3)
is_inside = False
for q in rectangles:
if inside(r, q):
is_inside = True
break
if not is_inside:
if not a == b:
rectangles.append(r)
for r in rectangles:
x, y, w, h = wrap_digit(r)
cv2.rectangle(img, (x, y), (x + w, y + h), (0, 255, 0), 2)
roi = thbw[y:y + h, x:x + w]
try:
digit_class = ANN.predict(ann, roi)[0]
except:
print("except")
continue
cv2.putText(img, "%d" % digit_class, (x, y - 1), cv2.FONT_HERSHEY_SIMPLEX, 1, (0, 255, 0))
cv2.imshow("thbw", thbw)
cv2.imshow("contours", img)
cv2.waitKey()
cv2.destroyAllWindows()
#######
import cv2
import pickle
import numpy as np
import gzip
"""OpenCV ANN Handwritten digit recognition example
Wraps OpenCV's own ANN by automating the loading of data and supplying default paramters,
such as 20 hidden layers, 10000 samples and 1 training epoch.
The load data code is taken from http://neuralnetworksanddeeplearning.com/chap1.html
by Michael Nielsen
"""
def vectorized_result(j):
e = np.zeros((10, 1))
e[j] = 1.0
return e
def load_data():
with gzip.open('C:\\Users\\64601\\PycharmProjects\\Ann\\mnist.pkl.gz') as fp:
# 注意版本不同,需要添加传入第二个参数encoding='bytes',否则出现编码错误
training_data, valid_data, test_data = pickle.load(fp, encoding='bytes')
fp.close()
return (training_data, valid_data, test_data)
def wrap_data():
# tr_d数组长度为50000,va_d数组长度为10000,te_d数组长度为10000
tr_d, va_d, te_d = load_data()
# 训练数据集
training_inputs = [np.reshape(x, (784, 1)) for x in tr_d[0]]
training_results = [vectorized_result(y) for y in tr_d[1]]
training_data = list(zip(training_inputs, training_results))
# 校验数据集
validation_inputs = [np.reshape(x, (784, 1)) for x in va_d[0]]
validation_data = list(zip(validation_inputs, va_d[1]))
# 测试数据集
test_inputs = [np.reshape(x, (784, 1)) for x in te_d[0]]
test_data = list(zip(test_inputs, te_d[1]))
return (training_data, validation_data, test_data)
def create_ANN(hidden=20):
ann = cv2.ml.ANN_MLP_create() # 建立模型
ann.setTrainMethod(cv2.ml.ANN_MLP_RPROP | cv2.ml.ANN_MLP_UPDATE_WEIGHTS) # 设置训练方式为反向传播
ann.setActivationFunction(
cv2.ml.ANN_MLP_SIGMOID_SYM) # 设置激活函数为SIGMOID,还有cv2.ml.ANN_MLP_IDENTITY,cv2.ml.ANNMLP_GAUSSIAN
ann.setLayerSizes(np.array([784, hidden, 10])) # 设置层数,输入784层,输出层10
ann.setTermCriteria((cv2.TERM_CRITERIA_EPS | cv2.TERM_CRITERIA_COUNT, 100, 0.1)) # 设置终止条件
return ann
def train(ann, samples=10000, epochs=1):
# tr:训练数据集; val:校验数据集; test:测试数据集;
tr, val, test = wrap_data()
for x in range(epochs):
counter = 0
for img in tr:
if (counter > samples):
break
if (counter % 1000 == 0):
print("Epoch %d: Trained %d/%d" % (x, counter, samples))
counter += 1
data, digit = img
ann.train(np.array([data.ravel()], dtype=np.float32), cv2.ml.ROW_SAMPLE,
np.array([digit.ravel()], dtype=np.float32))
print("Epoch %d complete" % x)
return ann, test
def predict(ann, sample):
resized = sample.copy()
rows, cols = resized.shape
if rows != 28 and cols != 28 and rows * cols > 0:
resized = cv2.resize(resized, (28, 28), interpolation=cv2.INTER_CUBIC)
return ann.predict(np.array([resized.ravel()], dtype=np.float32))
图片识别算法有问题
我也是一样的问题,对mnist的测试集进行测试,识别结果基本全是“8”,不知道为啥?