学习爬虫时候'ascii' codec can't encode characters报错,百度各种方法都试过了,测试后发现是ascii转不了utf-8
import urllib.request
import urllib.parse
import re
from bs4 import BeautifulSoup
import chardet
def main():
keyword=input("请输入关键词:")
keyword=urllib.parse.urlencode({"word":keyword})
response= \
urllib.request.urlopen("https://baike.baidu.com/search/word?%s"%\
keyword)
html=response.read()
soup=BeautifulSoup(html,"html.parser")
for each in soup.find_all(href=re.compile("view")):
content=''.join([each.text])
** url2 = ''.join(["https://baike.baidu.com", each["href"]])**
print(chardet.detect(str.encode(url2)))
response2 = urllib.request.urlopen(url2)
html2 = response2.read()
soup2 = BeautifulSoup(html2, "html.parser")
if soup2.h2:
content = ''.join([content, soup2.h2.text])
content = ''.join([content, "->", url2])
print(content)
if name=="__main__":
main()
我测试了一下,发现从 url2 = ''.join(["https://baike.baidu.com", each["href"]])这一句开始,它并没有全部编码成utf-8,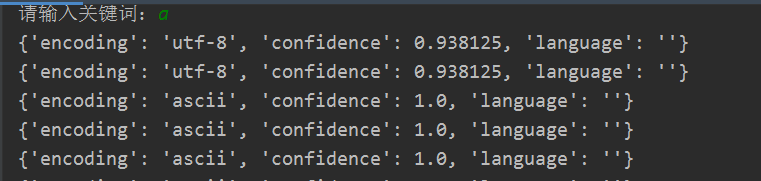 然后我用了encode转为utf-8还是不行,被折磨了一下午了,头都大了,请问有大哥能帮一下吗
然后我用了encode转为utf-8还是不行,被折磨了一下午了,头都大了,请问有大哥能帮一下吗
1.头部加#coding:utf-8
2.增加import sys
reload(sys)
sys.setdefaultencoding(‘utf-8’)
3.建议你别再win上跑,如果在win上跑,先decode('gbk')再encode('utf-8'),如果gbk不行尝试下ISO-8859-1