初学python,爬取京东商品数据时无法获取内容
- import requests from lxml import html
def spider_JD(sn):
url = 'https://search.jd.com/Search?keyword={0}'.format(sn)
html_doc=requests.get(url).text
selector=html.fromstring(html_doc)
ul_list2=selector.xpath('//div[@id="J_goodsList"]/ul/li')
print(len(ul_list2))
if name=='__main__':
spider_JD('9787115428028')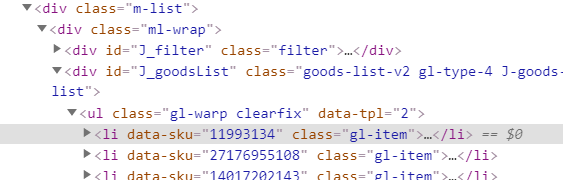
如图所示 可以看到很多li
但上述代码运行显示为0