为什呢matlab建立BP神经网络正确率很低?
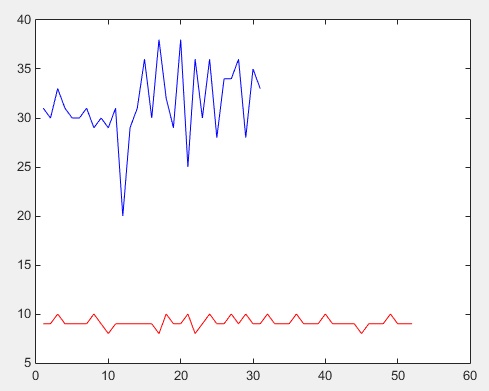
上图:
1.蓝色部分表示一类数据,红色部分表示二类数据
2.数据都只有一个特征向量为y轴的值
3.x轴为数据在训练集中的下标
问题:
本来应该是很简单的,利用一个特征向量(y轴的值)作为分类依据,将红色数据和蓝色数据分开。
然而,利用matlab建立BP神经网络,训练结果有时候非常好,测试正确率能达到98以上,有时候正确率只有20~30。
%训练样本
train_sample=[trainECG']; %21*25
%测试样本
test_sample=[testECG'];
%输出类别,建立HotCode
t1=[trainLabel'];
t2=[testLabel'];
train_result = ind2vec(t1);
test_result = ind2vec(t2);
net = newff(train_sample,train_result,4,{ 'tansig' 'purelin' } ,'traingdx');
net.trainParam.show=50; % 显示训练迭代过程
net.trainParam.epochs=15000; % 最大训练磁数
net.trainParam.goal=0.001; % 要求训练精度
net.trainParam.lr=0.02; % 学习率
net=init(net); %网络初始化
[net,tr]=train(net,train_sample,train_result); % 网络训练
result_sim=sim(net,test_sample); % 利用得到的神经网络仿真
result_sim_ind=vec2ind(result_sim);
correct=0;
for i=1:length(result_sim_ind)
if result_sim_ind(i)==t2(i);
correct=correct+1;
end
end
disp('正确率:');
correct / length(result_sim_ind)
没用过matlab,所以不敢说代码部分,只写过python的,根据你说的现象提两个可能的原因。
你的计算结果归根结底是模型训练结果不稳定,原因可能在样本数据本身:
①数据量太少,导致单个数据的不稳定对结果的影响大,如果你每次训练的训练集、测试集都重新随机划分就更突出了,如果你有一个数据,结果是有较大误差的,那么一旦这个样本放在了测试集,而测试集的样本很少,那么就很容易出现,这一次的测试集准确率特别低的情况。→→→解决方法:可以试着排除异常点,怎么排除可以查。
②数据不均衡,比如你的样本中有两类数据,第一类有100个,第二类就5个,那么很有可能你怎么学,第二类的特征也学不进去,如果某一次划分,测试集中第二类比较多,甚至5个你都分到测试集去了,那么当然这一次准确率就很低了