python bs4 find_all 有一行没有该属性 造成数据错位
想爬豆瓣读书的网页,在爬取评价星级时,某一条目没有这个层级的内容,所以使用BeautifulSoup的find_all功能时,数据错位了,怎么解决。可以用条件语句吗
titles=[]
authors=[]
ratings=[]
comments=[]
hds={'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36'}
source = requests.get('https://book.douban.com/tag/%E4%B8%AD%E5%9B%BD%E6%96%87%E5%AD%A6?start=280&type=R',headers=hds)
print(source.status_code)
print(source.text)
soup=bs.BeautifulSoup(source.content,'html.parser')
for t in soup.find_all('div',class_='info'):
for title in t.find_all('h2',class_=""):
print(title.text.strip())
titles.append(title.text.strip().replace('\n',''))
for author in soup.find_all("div",class_="pub") :
print(author.text.strip())
authors.append(author.text.strip())
for rating in soup.find_all('div',class_='star clearfix'):
if
print(rating.text)
ratings.append(rating.text.strip())
for comment in soup.find_all('span',class_='pl'):
print(comment.text.strip().replace('(','').replace('人评价)',''))
comments.append(comment.text.strip().replace('(','').replace('人评价)',''))
ratings.append(rating.text.strip())
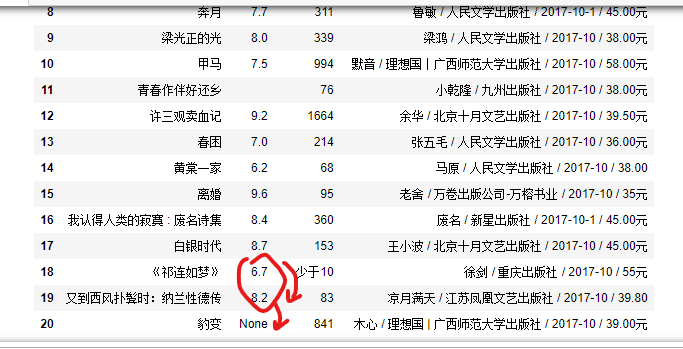
去掉空白???
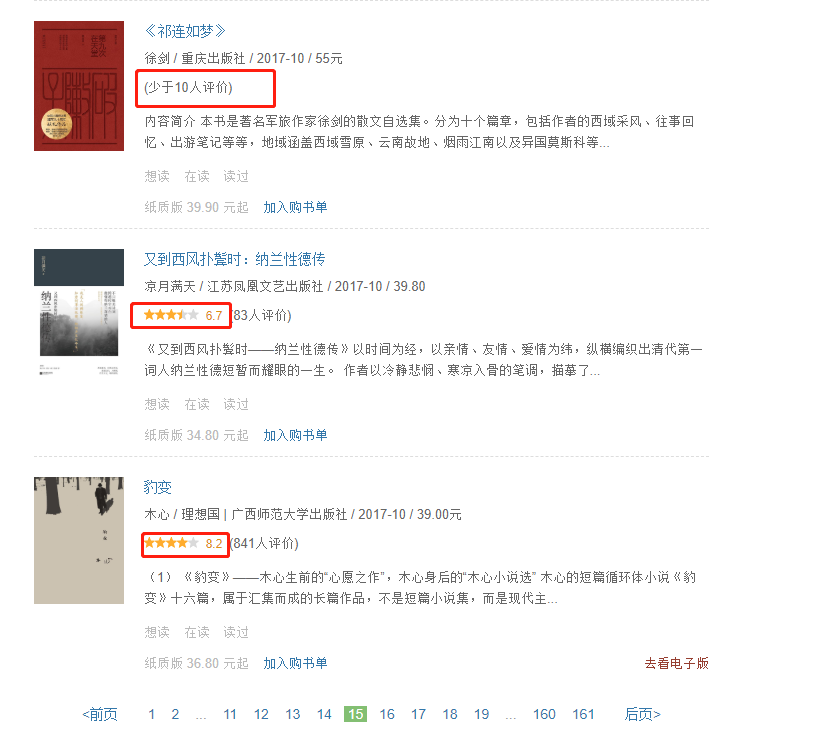
《祁连如梦》没有评分,是不是去掉空白的时候,直接去掉了??》