实在解决不了再请教了:TypeError: unsupported operand type(s) for -: 'list' and 'int'
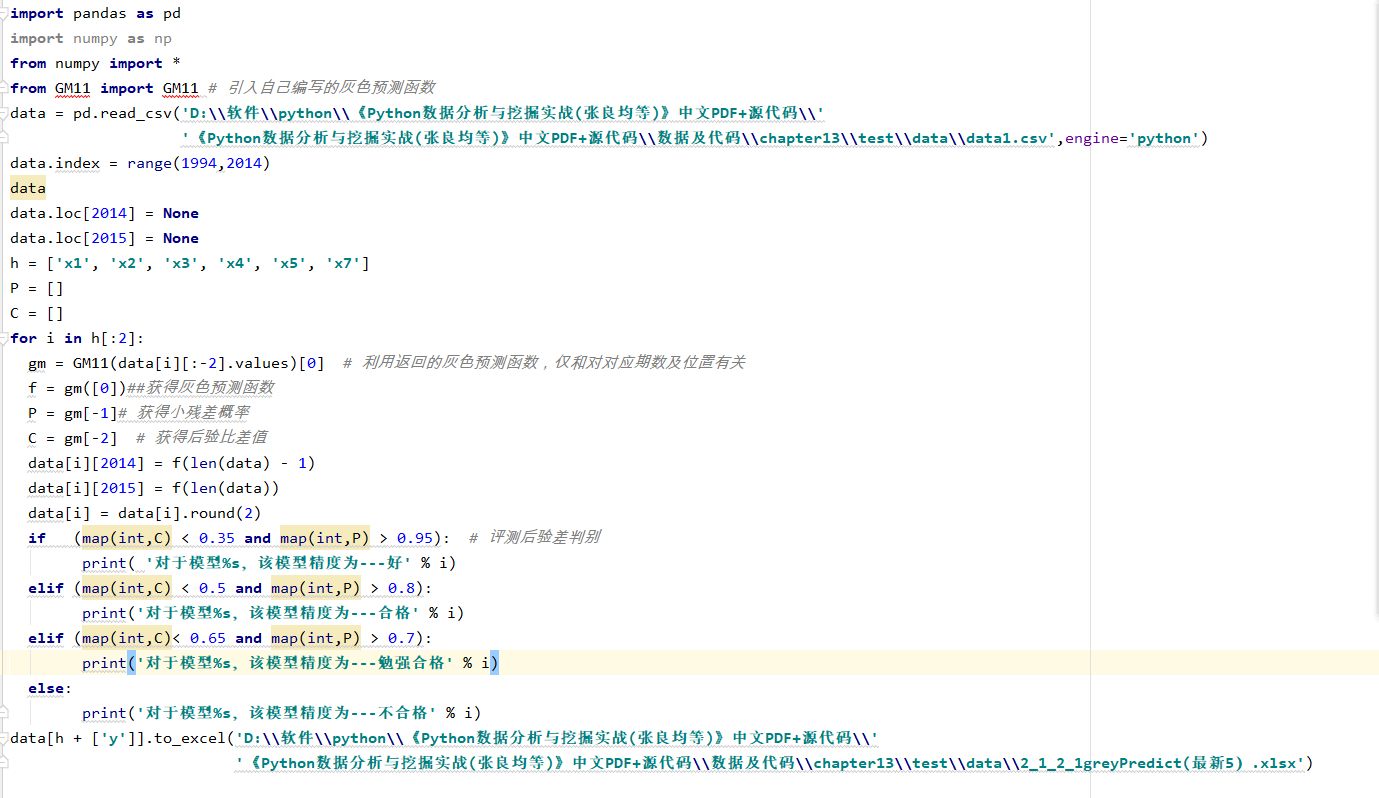

import pandas as pd
import numpy as np
from numpy import *
from GM11 import GM11 # 引入自己编写的灰色预测函数
data = pd.read_csv('D:\软件\python\《Python数据分析与挖掘实战(张良均等)》中文PDF+源代码\'
'《Python数据分析与挖掘实战(张良均等)》中文PDF+源代码\数据及代码\chapter13\test\data\data1.csv',engine='python')
data.index = range(1994,2014)
data
data.loc[2014] = None
data.loc[2015] = None
h = ['x1', 'x2', 'x3', 'x4', 'x5', 'x7']
P = []
C = []
for i in h[:2]:
gm = GM11(data[i][:-2].values)[0] # 利用返回的灰色预测函数,仅和对对应期数及位置有关
f = gm([0])##获得灰色预测函数
P = gm[-1]# 获得小残差概率
C = gm[-2] # 获得后验比差值
data[i][2014] = f(len(data) - 1)
data[i][2015] = f(len(data))
data[i] = data[i].round(2)
if (map(int,C) < 0.35 and map(int,P) > 0.95): # 评测后验差判别
print( '对于模型%s,该模型精度为---好' % i)
elif (map(int,C) < 0.5 and map(int,P) > 0.8):
print('对于模型%s,该模型精度为---合格' % i)
elif (map(int,C)< 0.65 and map(int,P) > 0.7):
print('对于模型%s,该模型精度为---勉强合格' % i)
else:
print('对于模型%s,该模型精度为---不合格' % i)
data[h + ['y']].to_excel('D:\软件\python\《Python数据分析与挖掘实战(张良均等)》中文PDF+源代码\'
'《Python数据分析与挖掘实战(张良均等)》中文PDF+源代码\数据及代码\chapter13\test\data\2_1_2_1greyPredict(最新5).xlsx')
f = gm([0])##获得灰色预测函数 这一行是不是多了可小口号啊
https://blog.csdn.net/qq_37960324/article/details/84138594
采纳率太差,就给你个链接自己去看
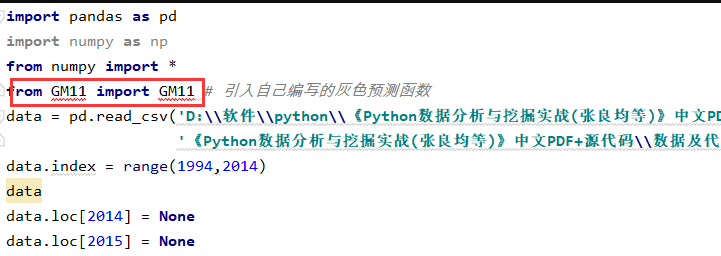
首先你这里引入就已经报错了,你的路径有问题,需要先看下你对应的路径,根据你对应文件所在目录,可以尝试下from .GM11 import GM11 这里根据你对应的目录加上一/两个点试下,最好是要看下你的目录结构是怎样的