如何解决ValueError: Length mismatch: Expected axis has 20 elements, new values have 19 elements
代码如下:
import numpy as np
import pandas as pd
from GM11 import GM11
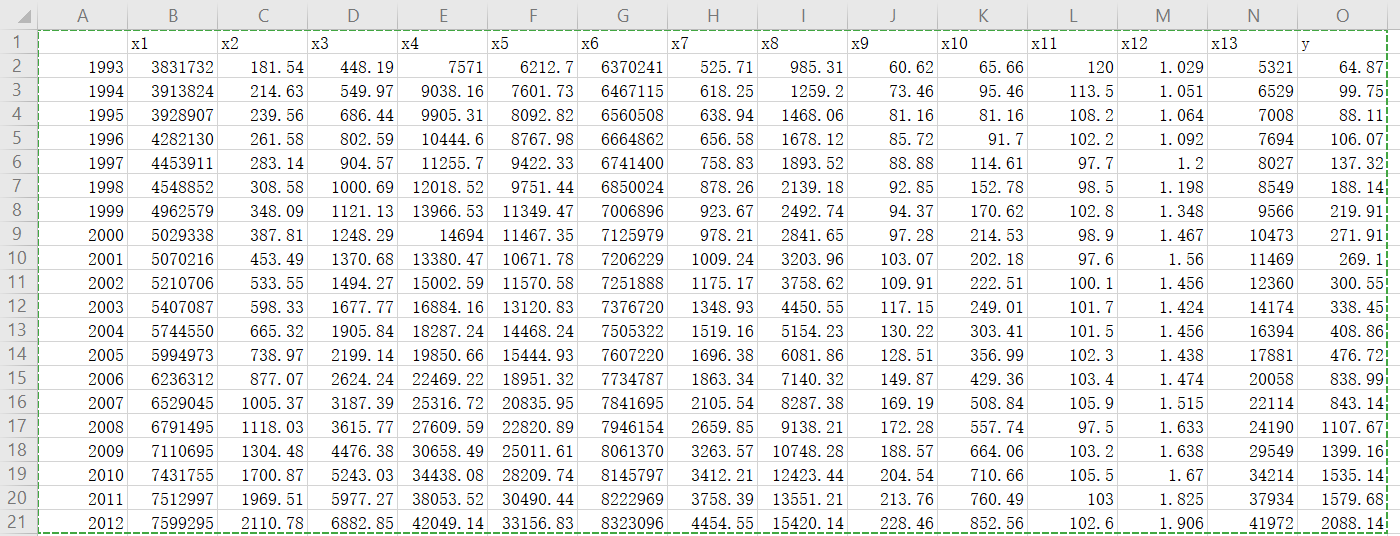
inputfile = 'D:\软件\python\《Python数据分析与挖掘实战(张良均等)》中文PDF+源代码\《Python数据分析与挖掘实战(张良均等)》中文PDF+源代码\数据及代码\chapter13\test\data\data1.csv' #输入的数据文件
outputfile = 'D:\软件\python\《Python数据分析与挖掘实战(张良均等)》中文PDF+源代码\《Python数据分析与挖掘实战(张良均等)》中文PDF+源代码\数据及代码\chapter13\test\data\data1_GM11.xls' #灰色预测后保存的路径
data = pd.read_csv('D:\软件\python\《Python数据分析与挖掘实战(张良均等)》中文PDF+源代码\《Python数据分析与挖掘实战(张良均等)》中文PDF+源代码\数据及代码\chapter13\test\data\data1.csv',engine='python') #读取数据
data.index = range(1993, 2012)
data.loc[2013] = None
data.loc[2014] = None
l = ['x1', 'x2', 'x3', 'x4', 'x5', 'x7']
for i in l:
f = GM11(data[i][arange(1993, 2012)].as_matrix())[0]
data[i][2013] = f(len(data)-1) #2013年预测结果
data[i][2014] = f(len(data)) #2014年预测结果
data[i] = data[i].round(2) #保留两位小数
data[l+['y']].to_excel(outputfile) #结果输出
if (C < 0.35 and P > 0.95): # 评测后验差判别
print ('对于模型%s,该模型精度为---好' % i)
elif (C < 0.5 and P > 0.8):
print ('对于模型%s,该模型精度为---合格' % i)
elif (C < 0.65 and P > 0.7):
print ('对于模型%s,该模型精度为---勉强合格' % i)
else:
print ('对于模型%s,该模型精度为---不合格' % i)
他都告诉你了你少了一个元素 data.index = range(1993, 2012) 这里错了 好好数数
对于编程新手来说,这种错误非常普遍。
它确切说明了所陈述的内容。 您期望的数据结构(列表,数组等您命名的)具有20个元素,但是新数据具有19个元素。 换句话说,在元素数彼此相等之前,您无法将一种数据结构打包到另一种数据结构中(在您的情况下为20个元素)。
请学习如何使用dir(),print()和type()函数在Python中调试(研究变量)-这些是您必须了解的基本函数。